






2
Apr
【不可思议的Word2Vec】 1.数学原理
By 苏剑林 | 2017-04-02 | 70167位读者 |对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
Word2Vec不可思议? #
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。
说到Word2Vec的“不可思议”,在Word2Vec发布之初,可能最让人惊讶的是它的Word Analogy特性,即诸如 king-man ≈ queen-woman 的线性特性,而发布者Mikolov认为这个特性意味着Word2Vec所生成的词向量具有了语义推理能力,而正是因为这个特性,加上Google的光环,让Word2Vec迅速火了起来。但很遗憾,我们自己去训练词向量的时候,其实很难复现这个结果出来,甚至也没有任何合理的依据表明一份好的词向量应该满足这个Word Analogy特性。不同的是,这里笔者介绍的若干个用途,可复现性是非常高的,读者甚至在小语料中训练一个Word2Vec模型,然后也能取到类似的结果。
数学原理:网络资源 #
有心想了解这个系列的读者,有必要了解一下Word2Vec的数学原理。当然,Word2Vec出来已经有好几年了,介绍它的文章数不胜数,这里我推荐peghoty大神的系列博客:
http://blog.csdn.net/itplus/article/details/37969519
另外,本博客的《词向量与Embedding究竟是怎么回事?》也有助于我们理解Word2Vec的原理。
为了方便读者阅读,我还收集了两个对应的PDF文件:
word2vector中的数学原理详解.pdf
Deep Learning 实战之 word2vec.pdf
其中第一个就是推荐的peghoty大神的系列博客的PDF版本。当然,英文好的话,可以直接看Word2Vec的原始论文:
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
[2] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
但个人感觉,原始论文并没有中文解释得清晰。
数学原理:简单解释 #
简单来说,Word2Vec就是“两个训练方案+两个提速手段”,所以严格来讲,它有四个备选的模型。
两个训练方案分别是CBOW和Skip-Gram,如图所示
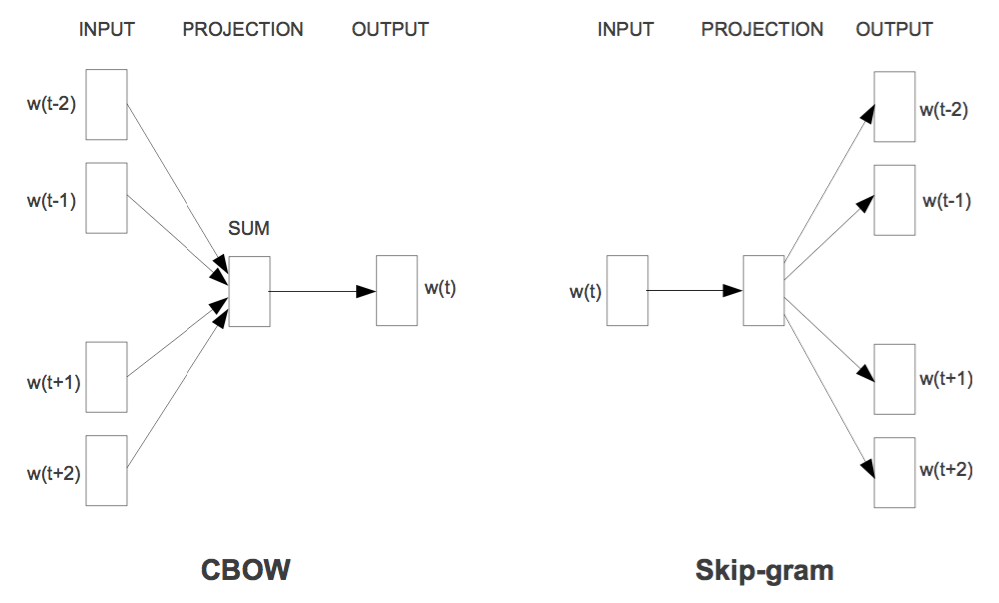
Word2Vec的两个模型
用通俗的语言来说,就是“周围词叠加起来预测当前词”($P(w_t|Context)$)和“当前词分别来预测周围词”($P(w_{others}|w_t)$),也就是条件概率建模问题了;两个提速手段,分别是层次Softmax和负样本采样。层次Softmax是对Softmax的简化,直接将预测概率的效率从$\mathcal{O}(|V|)$降为$\mathcal{O}(\log_2 |V|)$,但相对来说,精度会比原生的Softmax略差;负样本采样则采用了相反的思路,它把原来的输入和输出联合起来当作输入,然后做一个二分类来打分,这样子我们可以看成是联合概率$P(w_t,Context)$和$P(w_t,w_{others})$的建模了,正样本就用语料出现过的,负样本就随机抽若干。更多的内容还是去细看peghoty大神的系列博客比较好,我也是从中学习Word2Vec的实现细节的。
最后,要指出的是,本系列所使用的模型是“Skip-Gram + 层次Softmax”的组合,也就是要用到$P(w_{others}|w_t)$这个模型的本身,而不仅仅是词向量。所以,要接着看本系列的读者,需要对Skip-Gram模型有些了解,并且对层次Softmax的构造和实现方式有些印象。
请读者期待~
转载到请包括本文地址:https://www.kexue.fm/archives/4299
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 02, 2017). 《【不可思议的Word2Vec】 1.数学原理 》[Blog post]. Retrieved from https://www.kexue.fm/archives/4299
@online{kexuefm-4299,
title={【不可思议的Word2Vec】 1.数学原理},
author={苏剑林},
year={2017},
month={Apr},
url={\url{https://www.kexue.fm/archives/4299}},
}

April 8th, 2017
谢谢分享,很受用
February 9th, 2021
苏老师,如果以句子的联合概率最大化为出发点,CBOW 的 P(wt|context) 不能和整句的联合概率 P(w1, ...wt,...)等价,所以“周围词与当前词的关系”是CBOW和Skip-Gram的出发点,而不是整句化的联合概率?
补充下,联合概率可以拆解成word的单向条件概率乘积,但是,CBOW和skip-gram 是中间和两边的关系,这样的条件概率貌似推不出和联合概率等价;
通过噪声对比估计(负采样方案)学出来的模型其实一定程度上等价于联合概率分布,它不是基于自回归的条件分解来实现的。可以参考一下:https://kexue.fm/archives/5617