






24
Nov
生成扩散模型漫谈(三十一):预测数据而非噪声
By 苏剑林 | 2025-11-24 | 32749位读者 |时至今日,LDM(Latent Diffusion Models)依旧是扩散模型的主流范式。借助Encoder对原始图像进行高倍压缩,LDM能显著减少训练与推理的计算成本,同时还能降低训难度,可谓一举多得。然而,高倍压缩也意味着信息损失,而且“压缩、生成、解压缩”的流水线也少了些端到端的美感。因此,始终有一部分人执着于“回到像素空间”,希望让扩散模型直接在原始数据上完成生成。
本文要介绍的《Back to Basics: Let Denoising Generative Models Denoise》正是这一思路的新工作,它基于原始数据往往处于低维子流形这一事实,提出模型应预测数据而不是噪声,由此得到“JiT(Just image Transformers)”,显著地简化了像素空间的扩散模型架构。
信噪之比 #
毋庸置疑,当今扩散模型的“主力军”依然是LDM,即便是前段时间颇为热闹的RAE,也只是声称LDM的Encoder已经“过时”了,要给它换一个新的更强的Encoder,但依然没改变“先压缩后生成”这一模式。
之所以有如此局面,除了因为LDM能显著降低大图生成的计算成本外,还有一个关键原因是,在相当长时间内,研究人员发现直接像素空间做高分辨率的扩散生成似乎存在一些“固有困难”,具体表现为将低分辨率下行之有效的配置(比如Noise Schedule)用于高分辨率扩散模型的训练,最终结果会明显变差,具体表现为收敛速度慢、FID不如低分辨率模型等。
后来,Simple Diffusion等工作意识到了导致这一现象的关键原因:同一Noise Schedule用到更高分辨率的图像上,其信噪比本质上是增加的。具体来说,当我们将同样强度的噪声施加到小图和大图,然后缩放到同一大小,那么大图看起来会更清晰。因此,用同样的Noise Schedule去训练高分辨率扩散模型时,去噪的难度无形之中变低了,于是带来了训练效率低下、效果不佳等问题。

同一noise不同分辨率的信噪比
意识到这个原因后,解决办法也就不难想了:调整高分辨率扩散模型的Noise Schedule,提高相应的噪声强度,以对齐每一步的信噪比即可。更详细的讨论可以参考之前的博客《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》。自此以后,像素空间中的扩散模型便逐渐追上了LDM的效果,开始体现出自己的竞争力。
模型瓶颈 #
然而,尽管在指标(如FID或IS)方面像素空间的扩散模型已经追上LDM了,但仍绕不开另一个让人困惑的问题:为了得到与低分辨率模型相近的指标,高分辨率模型必须付出更多的计算,比如更多的训练步数、更大的模型、更大的Feature Map等。
可能有读者觉得没什么:生成更大的图需要更大的成本,这不是很合理?咋看之下是有道理,但仔细想想就会发现并不科学。大图生成本质上也许更为困难,但至少对FID/IS等指标来说不应该,因为这俩指标都是将生成结果缩放到特定大小后才计算的。这意味着如果我们有一批小图,那么想要得到一批FID/IS都不变的大图是很容易的,只需要将每张小图都UpSample一下就行了,几乎零额外成本。
这时候可能会有人指出“UpSample得到的大图会缺细节啊”,没错,这就是刚才说的“大图生成本质上也许更为困难”,因为它需要生成更多的细节。但是,UpSample这个操作,至少对FID和IS是不变的。这就意味着,理论上来说,我付出同等的算力,应该至少能得到一个FID/IS都大致相同的、但细节可能不足的大图生成模型。但事实并非如此,很多时候我们只能得到一个全方面明显更糟糕的模型。
让我们来将这个问题具体化一下。假设Baseline是一个$128\times 128$的小图模型,它按$8\times 8$的Patch对输入进行Patchify,线性投影到768维,再送入一个 hidden_size=768 的ViT,最后线性投影回图片大小,这个配置在$128\times 128$分辨率上工作良好。接着我们要做的$512\times 512$的大图生成,我只需要将Patch Size改为$32\times 32$,那么除了输入输出的投影略为变大后,整体计算量几乎不变。
现在的问题是:用这样的一个计算成本大致相同的模型去训$512\times 512$的扩散模型,我们能得到跟$128\times 128$分辨率模型一样的FID/IS吗?
低维流形 #
对于JiT之前的扩散模型,答案是大概率不行,因为这样的模型在高分辨率时具有低秩瓶颈。
此前扩散模型有两种主流范式,一是像DDPM那样预测噪声,一是像ReFlow那样预测噪声与原图之差(速度),二者的回归目标都有噪声。噪声向量是独立重复地从正态分布采样出来的,它能“铺满”整个空间,用数学的话说它的支撑(Support)是全空间。这样一来,模型要想成功预测任意噪声向量,那么至少不能存在低秩瓶颈,否则连恒等映射都无法实现,更不用说去噪了。
回到刚才的例子,当Patch Size改为$32\times 32$后,输入维度是$32\times 32\times 3 = 3072$,再降维投影到768维,这自然是不可逆的,因此如果我们还是用它预测噪声或速度的话,就会因为低秩瓶颈而效果不佳。这里的关键问题是实际模型并非真的具有万能拟合能力,而是或多或少存在一些拟合瓶颈。
说到这里,其实JiT的核心改动已经呼之欲出了:
相比于噪声,原始数据的有效维度往往更低,也就是说原始数据处于一个更低维的子流形中,这意味着模型预测数据会比预测噪声更加“轻松”,因此模型应优先选择预测原始数据,尤其是网络容量有限时。
说白了,就是原始数据比如图像往往具有特定的结构,所以预测起来更简单,因此模型应该预测图像,这样可以将低秩瓶颈的影响降到最低,甚至可能将劣势转化为优势。
分开来看,这里的每一个小点都不是新的:噪声的支撑是全空间、原始数据往往处于低维流形,这些结论某种程度上已是“广为人知”;至于直接用模型预测图像而不是噪声,这也不是第一次尝试。但原论文最了不起的地方,在于把这些点同时串联起来,形成一个合理的解释,令人拍案叫绝的同时又觉得无法反驳,反而有种“本该如此”的感觉。
实验分析 #
当然,虽然看上去很合理,但到目前为止它顶多算是猜测,接下来就是通过实验来验证它。JiT里边的实验很多,但笔者认为最值得关注的是下面三个。
首先,我们现在有三个可选的预测目标,分别是噪声、速度、数据,然后它们又可以细分为模型的预测目标和损失函数的回归目标,所以一共有9种组合。以ReFlow为例,设$\boldsymbol{x}_0$是噪声,$\boldsymbol{x}_1$是数据,它的训练目标是
\begin{equation}\mathbb{E}_{\boldsymbol{x}_0\sim p_0(\boldsymbol{x}_0),\boldsymbol{x}_1\sim p_1(\boldsymbol{x}_1)}\bigg[\bigg\Vert \boldsymbol{v}_{\boldsymbol{\theta}}\big(\underbrace{(\boldsymbol{x}_1 - \boldsymbol{x}_0)t + \boldsymbol{x}_0}_{\boldsymbol{x}_t}, t\big) - (\boldsymbol{x}_1 - \boldsymbol{x}_0)\bigg\Vert^2\bigg]\end{equation}
其中$\boldsymbol{v}=\boldsymbol{x}_1 - \boldsymbol{x}_0$即速度,所以这是一个回归目标为速度的损失($\boldsymbol{v}\text{-loss}$),如果我们用一个神经网络去建模$\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)$,那么模型的预测目标也是速度($\boldsymbol{v}\text{-pred}$),如果我们根据$\boldsymbol{x}_1 - \boldsymbol{x}_0=\frac{\boldsymbol{x}_1 - \boldsymbol{x}_t}{1-t}$,将$\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)$参数化为$\frac{\text{NN}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \boldsymbol{x}_t}{1-t}$,那么$\text{NN}$的预测目标就是数据$\boldsymbol{x}_1$($\boldsymbol{x}\text{-pred}$)。
这9种组合在有/无低秩瓶颈的ViT模型上的效果分别如下图左:
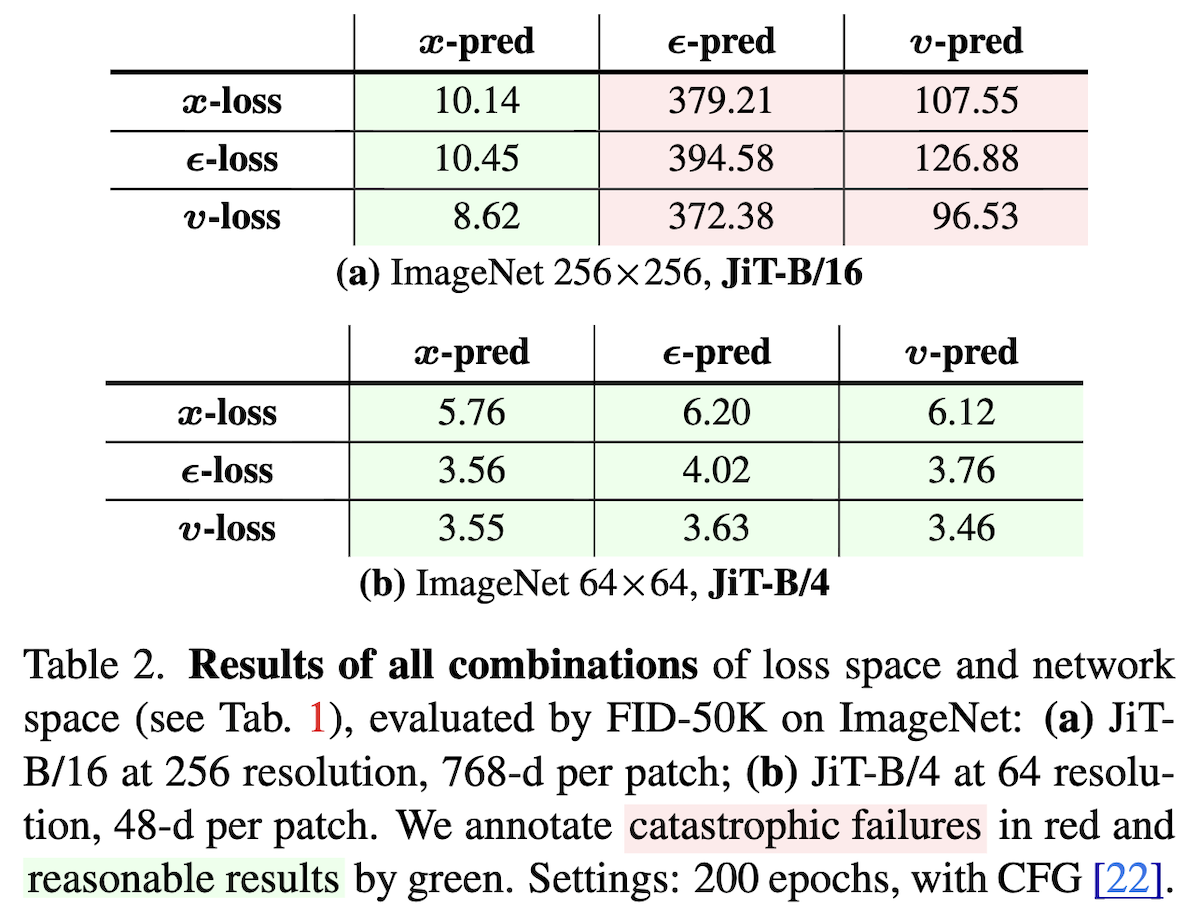
有/无低秩瓶颈时x/ε/v-pred/loss的效果差别
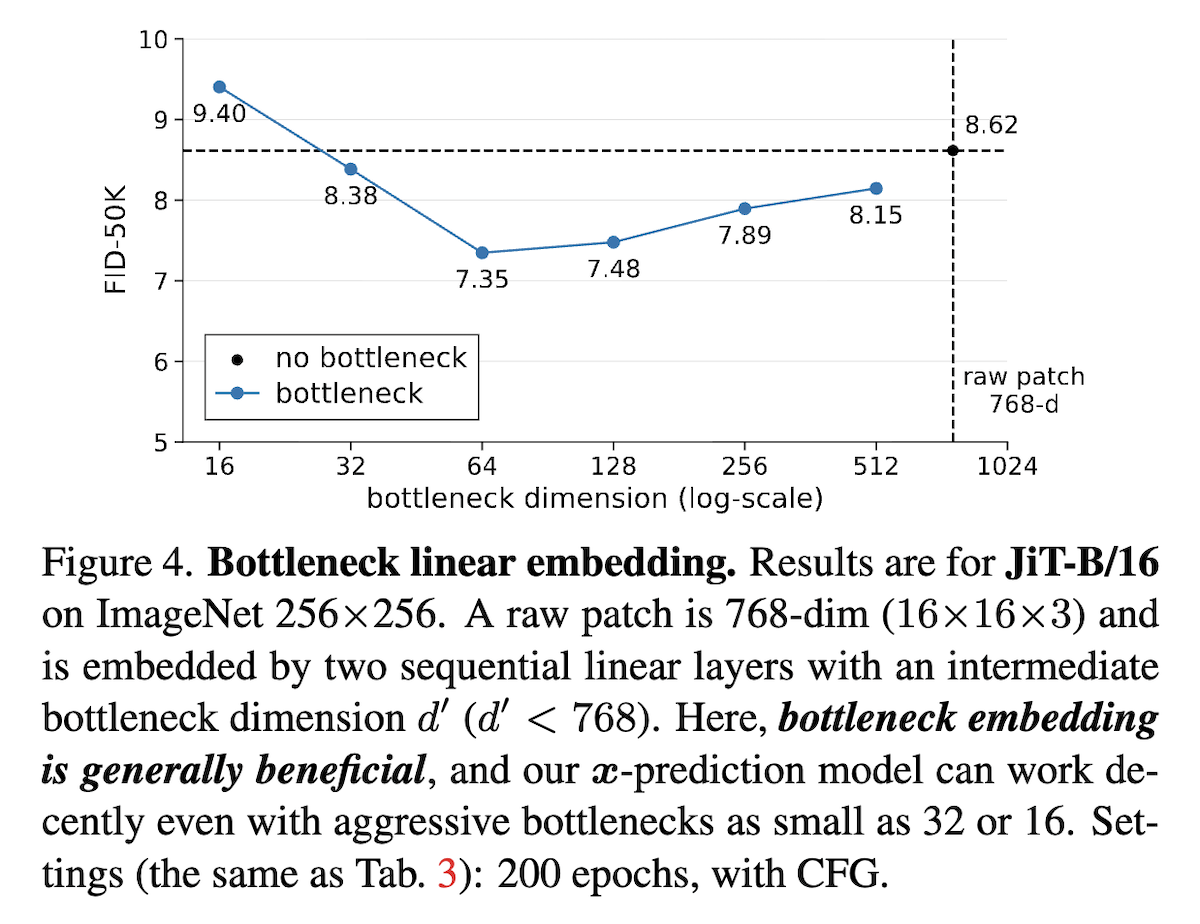
增加适当的低秩瓶颈,反而有利于FID
可以看到,如果没有低秩瓶颈(b),那么9种组合差别不大,但如果模型存在低秩瓶颈(a),则只有预测目标是数据($\boldsymbol{x}\text{-pred}$)才能成功训练,至于回归目标的影响则比较次要,这就肯定了预测数据的必要性。还有,论文发现主动给$\boldsymbol{x}\text{-pred}$的JiT增加适当的低秩瓶颈,反而有利于FID,如上图右。
进一步地,下表验证了通过预测数据,确实可以在相近的计算量和参数量下,得到相近FID的不同分辨率模型:

不同分辨率、相近的计算量和参数量,也可以得到相近的FiD指标
最后,笔者也自己对比了一番,在CelebA HQ上用大Patch Size的ViT模型分别做$\boldsymbol{x}\text{-pred}$和$\boldsymbol{v}\text{-pred}$的效果对比如下(训得比较糙,对比看就行):

预测原图的生成效果

预测速度的生成效果
延伸思考 #
更多的实验结果大家自行看原论文了,这一节我们来讨论一下,JiT给扩散模型带来了什么变化。
首先,它并没有刷新SOTA。从论文中的实验表格可以看出,就生成ImageNet图像这个任务而言,它没有带来新的SOTA,但跟最优结果的差距也不大,因此可以认为它的效果也是SOTA级别的,但总之没有明显超越它。另一方面,我们将已经是SOTA的非$\boldsymbol{x}\text{-pred}$模型改为$\boldsymbol{x}\text{-pred}$,大概率也不会得到显著更优的结果。
不过,它也许能够降低SOTA的成本。让模型预测数据,缓解了低秩瓶颈等问题的影响,使得我们可以重新审视那些曾因效果不佳而被弃用的轻量设计,或者以较低的额外训练成本,将低分辨率的SOTA模型“升级”成高分辨率模型。从这个角度看,JiT真正解决的问题是从低分辨率到高分辨率的可迁移性。
此外,JiT使得视觉理解和生成的架构更为统一。事实上,JiT基本就是视觉理解所用的ViT模型,跟文本LLM的GPT架构也大同小异,架构的统一更利于我们设计理解与生成于一体的多模态模型。相比之下,此前扩散模型的标准架构是U-Net,它包含多级上下采样和多条跨尺度直通连接,结构相对复杂。
从这个角度看,JiT可谓是准确找到了U-Net中最关键的一条直通连接。还是ReFlow的例子,如果我们按照建模$\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)$来理解,那么JiT中有$\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)=\frac{\text{NN}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \boldsymbol{x}_t}{1-t}$,额外的$-\boldsymbol{x}_t$正是从输入到输出的一条直通连接。U-Net则是不去管哪个连接关不关健,它直接给每个上/下采样的Block都加上这样一条直通连接。
最后,插个“题外话”。由JiT笔者还想到了DDCM,它需要预采样一个“$T \times \text{img_size}$”的巨大矩阵作为Codebook,笔者曾尝试用有限个随机向量的线性组合来模拟它,但以失败告终,这个经历让笔者深刻体会到独立同分布噪声是撑满整个空间的、不可压缩的。所以,当看到JiT提出“数据处于低维流形、预测数据比预测噪声更容易”观点时,笔者几乎瞬间就理解并接受了它。
文章小结 #
本文简单介绍了JiT,它基于原始数据往往处于低维子流形这一事实,提出模型应优先选择预测数据而不是噪声/速度,这样能降低扩散模型的建模难度,减少模型崩溃等负面结果的可能性。
转载到请包括本文地址:https://www.kexue.fm/archives/11428
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 24, 2025). 《生成扩散模型漫谈(三十一):预测数据而非噪声 》[Blog post]. Retrieved from https://www.kexue.fm/archives/11428
@online{kexuefm-11428,
title={生成扩散模型漫谈(三十一):预测数据而非噪声},
author={苏剑林},
year={2025},
month={Nov},
url={\url{https://www.kexue.fm/archives/11428}},
}

November 24th, 2025
大佬,感谢您的讲解。我一直对图像任务有一些困惑。很多文章都有做出比如图像是一个低维流行的假设。然后我知道LDM大概就是基于这一点所提出来的。
但我的一个困惑在于,如果我们对图像施加轻微的噪声,那对人眼来没区别,但是由于增加了噪声,之前低维流形的假设就被破坏了。考虑所有噪声的组合(只施加一次噪声,不考虑多次施加噪声),图像实际上就是覆盖高维空间的。(类似于多个高维球的并集这种感觉)。
所以,在计算机视觉的领域内,究竟什么是一个“纯粹的图像”?
比如Flow Matching和DDPM的推导里,都有假设它们的重点分布是某个以原图$x_0$为中心的高斯分布(方差很小,所以比较集中),但这一假设就直接破坏了低维流形的性质。但如果不引入这个假设的话,那么原图的分布是多个$\delta$分布的和,而非某个绝对连续的分布。这就破坏了最优传输里Brenier定理的核心前提,所以我个人觉得Flow Matching的直线插值的理论基础就被破坏了。所以感觉很矛盾。
不知道您是如何思考这个问题的,想和大佬您探讨一下。
这里维数实际上是指有效维数,我不大清楚这里怎么严格表达,但理解的话,我们可以类比一下矩阵的有效秩概念。
举个例子,假设$\boldsymbol{x}$是一个$d$维的非零列向量,那么$\boldsymbol{x}\boldsymbol{x}^{\top}$就是一个rank-1矩阵,这个很好理解,我们将它加上一个单位阵的$\sigma$倍($\sigma > 0$),得到
$$\boldsymbol{x}\boldsymbol{x}^{\top} + \sigma \boldsymbol{I}$$
容易证明,对于任意$\sigma > 0$,这个新矩阵都是满秩矩阵;然而,假设$\sigma$非常小,比如$\sigma=10^{-100}$,那么$\boldsymbol{x}\boldsymbol{x}^{\top} + \sigma \boldsymbol{I}$跟$\boldsymbol{x}\boldsymbol{x}^{\top}$在实际使用中会有实质区别吗?显然没有。但从数学上,这两个确实又是满秩和rank-1的巨大区别。
这表明,线性代数的秩的概念,不是很好能度量我们关于线性无关数量的实际体验,所以就有了有效秩的概念,参考 https://kexue.fm/archives/10847 ,它跟线性代数的秩概念相似,但更不容易受到轻微扰动的影响。
回到维数和流形上,类似地,这里应该存在一个“有效维数”的概念,像你说的给输入加轻微噪声扰动的操作,它不会明显改变有效维数。更具体点,比如MNIST图像是一个28*28=784维的向量,但你可以用PCA降到很低维,即便加上轻微的噪声扰动,这个降维还是成立的,但如果噪声太大的话就不行了。
不过,即便是矩阵的有效秩概念,也没有一个标准定义,所以有效维数估计也没有~
谢谢苏神~,这个思路对我很有启发。
也可以从natural image space的角度去理解。对于一张256x256x3的图片,理论上的图片张数有$3^{256 \times 256}$,但实际上人们观测到的图片数约等于 人类存在的时间x人口数量 (可以估算出来是一个非常小的值)。
这个估算虽然看起来非常vanilla,但启发了CV领域许多非常早期的研究。例如人们发现,natural image具有特殊的性质,比如Power Law, Kurtosis and Sparsity,进而开始将natural image和物理里的一些统计模型做类比,例如Ising model, markov random field。研究表明,自然图像能够被热力学和统计物理的系综理论所刻画(可能也就是jianlin说的有效rank),i.e.
What features and statistics are characteristic of a texture pattern, so that texture pairs that share the
same features and statistics cannot be told apart by pre-attentive human visual perception?
我觉得这也是从Filters,Energy-based models到Conv的一个直接演进。
如果感兴趣的话可以看Computer Vision: Statistical Models for Marr’s Paradigm,属于比较有科学范的AI研究了。
这个角度有点意思啊,有种“吾生也有涯,而知也无涯”的感觉了,感谢分享。
顺便更正一下:256x256x3的RGB图片,理论上的张数应该是$256^{256\times 256\times 3}$才对。
Get! 最近Vincent Sitzmann对video generation的分享(知乎上可以搜到)也提到了Diffusion Forcing/History Guidance背后的insight,提到了power spectral density, which是自然图像独有的性质,即大部分图片能量集中在低频区域,随着频率升高,能量呈线性衰减~而white noise的功率谱密度是平坦的,物理还是太有趣了
谢谢分享,我去好好补习一下。
November 24th, 2025
苏神似乎在讨论局部本征维度估计?
https://proceedings.mlr.press/v162/tempczyk22a/tempczyk22a.pdf
嗯,应该有很多相关工作,直接对协方差矩阵矩阵做SVD其实也可以估算,不过这就只适合线性流形了。
谢谢苏神回复。不过我感觉目前一般图像任务的数据集的样本数量似乎支撑不了连续的流形(尤其是被标准化过后的数据,被re-scale到高斯球面上后),有点难以利用流形的曲率和拓扑特性。
可以是经过非线性甚至非光滑的投影,才能得到连续流形,总之总可以强行辩解(狡辩)的。
November 26th, 2025
苏老师您好,我有个疑惑,在进行高分辨率图像训练时,如文中提到的512x512,进行patchify时为什么一定要按照32x32,而不能按照原先的8x8?理论上按照8x8应该就不会存在低秩问题了吧。当然按照8x8应该会增加不少计算量,但如果机器能够hold得住的情况下是否应该先按照8x8方式而非一定要强行增大patch_size?
好问题。这里边有很多值得思考的地方。
首先,如果patch size不变,那么序列长度就变成了原来的16倍,计算量也增加到了16倍,如果是Attention的话,最大可能要去到16x16=256倍。那么一张512x512的图,信息量是128x128的多少倍呢?值得我们我们付出16倍甚至256倍的计算量吗?
这个问题的答案不是固定的。如果是任意的512x512图片 vs 任意的128x128图片,那么平均信息量可能真的有16倍以上;然而,目前我们的评测任务,都是同一数据集下不同分辨率的图,小图实际上是大图缩小而来,这种情况下,512x512的图不见得有128x128图的16倍信息量。
当然,这里还得看我们关注什么,如果关注局部细节(比如你关心头发丝的生成效果),那么结论肯定不一样。如果我们只关心评测指标FID或IS,那么几乎可以肯定它没有16倍信息量,因为它们具有放大不变性。所以,为了得到相同的FID/IS指标,付出16倍甚至更多倍的计算,是非常不科学的事情。
感谢苏老师的解答!
November 28th, 2025
我觉得这个work摆脱了two stages,真正做到E2E,让feature extraction/embedding 和 flow matching 之间可以传递gradient,不用被VAE锁死上限,这个很了不起。虽然现在没有beat SOTA,但是这个框架未来很有潜力。感谢你的分享!
同感
December 2nd, 2025
重新复习了下DDPM的论文,原文中作者在消融实验这里也尝试过预测x0和ϵ,得出的结论是预测噪声效果更好,很想请教下苏神怎么看待这样相反的结果呢,可以认为是在小图上低秩作用不明显但在大图上低秩效果更加显著吗?
\begin{align*}
\mu_q &= \frac{\sqrt{\alpha_{t-1}} \beta_t x_0 + \sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1}) x_t}{1 - \bar{\alpha}_t} \\
&= \frac{\sqrt{\alpha_{t-1}} \beta_t \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon}{\sqrt{\bar{\alpha}_t}} + \sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1}) x_t}{1 - \bar{\alpha}_t} \\
&= \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon \right)
\end{align*}
没有低秩瓶颈的前提下,预测哪个优是不确定的。此外,DDPM的消融实验似乎也没有“$\boldsymbol{x}\text{-pred}$ + $\boldsymbol{\varepsilon}\text{-loss}$”这个组合。
了解了,感谢回答
December 2nd, 2025
打错了,应该是采样预测前一步的分布均值μ
December 30th, 2025
我看这篇论文之前觉得会很厉害,但是看完之后有一种还好的感觉,好像之前看过的生成模型论文里面提到过直接预测数据但是没有这篇论文这么深入,好像一种水到渠成的感觉,总之给我最大的感觉就是成本降低了,普通学生也可以在自己电脑上面尝试一下高分辨率图片生成了。
January 4th, 2026
苏老师您好,感谢您的分享,每次看您的文章都收获颇丰!我有一个不太理解的点,您在文章中说如果有一批小图,那么想要得到一批FID不变的大图只需要将每张小图都UpSample一下就行了,$\text{FID} = ||\mu_r - \mu_g||^2 + \mathrm{Tr}(\Sigma_r + \Sigma_g - 2(\Sigma_r \Sigma_g)^{1/2})$,其中的特征来自于Inception-V3或其他网络的特征分布,UpSample后不会改变这些特征从而改变结果吗?
Inception-V3的输入大小是299*299*3,也就是说,不管你原始图像是多大(哪怕是cifar10这种只有32*32的),都要reshape成299*299后再输入到Inception-V3抽特征,然后去算FID。
所以很明显,小图算FID也是要放大到299*299,你将小图UpSample成大图(比如1024*1024),它还是要缩小到299*299,一般情况下UpSample再缩小,图片是无损的,所以FID对UpSample变换是不变的。