






17
Apr
基于流式幂迭代的Muon实现:5. 延伸
By 苏剑林 | 2026-04-17 | 472位读者 | 引用本系列文章的主题是“流式幂迭代”,顾名思义,它由“流式”和“幂迭代”两部分构成,其中“幂迭代”是求矩阵SVD的一种经典的多步迭代方案,而“流式”则是指将原本需要多步迭代的算法平摊到每一步训练上,使得计算成本变得可以接受,其核心思想在于:与其一次性完成复杂计算,不如在训练过程中持续逼近目标。
作为该系列的延伸,本文将介绍另外一些“流式”思想的应用,进一步展示如何通过流式转化将相对昂贵的操作巧妙地融入训练流程。
正交投影
有些场景下,我们会希望约束某些参数矩阵的正交性。正交矩阵具有良好的数值稳定性,可以避免一些数值爆炸或消失问题,同时在某些设计中能带来更好的理论保证。当然,哪些地方适合约束参数为正交矩阵,我们需要具体场景具体分析,这里不做展开。
13
Apr
基于流式幂迭代的Muon实现:4. 原理
By 苏剑林 | 2026-04-13 | 827位读者 | 引用经过《基于流式幂迭代的Muon实现:1. 初识》、《基于流式幂迭代的Muon实现:2. 加速》和《基于流式幂迭代的Muon实现:3. 雕琢》三篇文章,想必大家已经对流式幂迭代(Streaming Power Iteration)的思想、实现、加速等细节有所了解,总的来说,这称得上是一种颇有竞争力的Muon实现方式,并且得益于它直接近似计算SVD,所以它还具备更好的拓展性。
受限于篇幅,当时我们对相关运算的数学原理描述得相对简略,因此在这篇文章中,我们补充部分关于幂迭代和QR分解的数学推导,以建立更完整的理论图景。不过,这里的推导依然是侧重解释性而非严格性,主要是为了帮大家(包括笔者)理清思路,还请专业读者海涵。
共轴等价
在开始推导之前,我们需要先引入“共轴等价”的概念。对于矩阵$\boldsymbol{A},\boldsymbol{B}\in\mathbb{R}^{n\times m}$,如果存在一个符号矩阵$\boldsymbol{S}$满足$\boldsymbol{A} = \boldsymbol{B}\boldsymbol{S}$,那么称$\boldsymbol{A}$与$\boldsymbol{B}$“共轴等价(Coaxial Equivalent)”,它们互为对方的“共轴矩阵”。这里的“符号矩阵(Signature matrix)”是指为对角线为$\pm 1$的对角矩阵,即$\newcommand{diag}{\mathop{\text{diag}}}\diag(\pm 1, \pm 1, \cdots, \pm 1)$。
7
Apr
基于流式幂迭代的Muon实现:3. 雕琢
By 苏剑林 | 2026-04-07 | 1426位读者 | 引用回顾前两篇文章《基于流式幂迭代的Muon实现:1. 初识》和《基于流式幂迭代的Muon实现:2. 加速》,我们引入了Muon的流式幂迭代(Streaming Power Iteration)实现方案,初步验证了它的可行性,并进一步讨论了核心运算——QR分解——的加速,使其接近Newton-Schulz迭代实现的效率。
在这篇文章中,我们不再局限于优化单步的QR分解,而是从更整体的视角看待流式幂迭代,并结合具体的计算背景,对其实现细节做进一步的“精雕细琢”,尽可能减少计算瓶颈,使其效率趋近理论极限。
现有结果
流式幂迭代本质上是“边训练边SVD”,它的想法是通过幂迭代来求SVD,并通过缓存上一步的结果,将计算平摊到每一步训练上,使得在优化器中嵌入SVD成为可能。至于Muon,只不过是它的一个基本应用,因为Muon的核心运算$\newcommand{msign}{\mathop{\text{msign}}}\msign$最基本的实现方式就是SVD。具体来说,Muon的更新公式是
26
Mar
基于流式幂迭代的Muon实现:2. 加速
By 苏剑林 | 2026-03-26 | 2741位读者 | 引用在第一篇文章《基于流式幂迭代的Muon实现:1. 初识》中,笔者将流式幂迭代(Streaming Power Iteration)单独抽象出来,作为一种新的Muon实现方式。由于新方案是直接对SVD进行近似计算,所以相比基于Newton-Schulz迭代的标准实现,它具有更丰富的拓展空间,值得继续深入研究。
从计算上看,新方案的主要变化是Newton-Schulz迭代换成了$\newcommand{QR}{\mathop{\text{QR}}}\QR$分解,这带来了一些降速。上篇我们已经讨论了一些基本的加速手段,但尚未比肩标准实现。这篇文章我们继续研究$\QR$的加速,以求尽可能缩小差距。
流式迭代
我们将沿用第一篇文章的所有概念和记号,有相关疑惑的读者请先往前翻看一下。首先,Muon的更新公式是
\begin{equation}\newcommand{msign}{\mathop{\text{msign}}}\begin{aligned}
\boldsymbol{M}_t =&\, \beta\boldsymbol{M}_{t-1} + \boldsymbol{G}_t \\[5pt]
\boldsymbol{W}_t =&\, \boldsymbol{W}_{t-1} - \eta_t [\msign(\boldsymbol{M}_t) + \lambda \boldsymbol{W}_{t-1}] \\
\end{aligned}\end{equation}
19
Mar
Attention Residuals 回忆录
By 苏剑林 | 2026-03-19 | 19368位读者 | 引用这篇文章介绍我们的一个最新作品Attention Residuals(AttnRes),顾名思义,这是用Attention的思路去改进Residuals。
不少读者应该都听说过Pre Norm/Post Norm之争,但这说到底只是Residuals本身的“内斗”,包括后来很多Normalization的变化都是如此。比较有意思的变化是HC,它开始走扩大残差流的路线,但也许是效果上的不稳定,并没有引起太多反响。后来的故事大家可能都知道了,去年底DeepSeek的mHC改进了HC,并在更大规模实验上验证了它的有效性。
相比于进一步扩大残差流,我们选择了另一条激进的路线:直接在层间做Attention来替代Residuals。当然,全流程走通还是有很多细节和工作的,这里就简单回忆一下相关的心路历程。
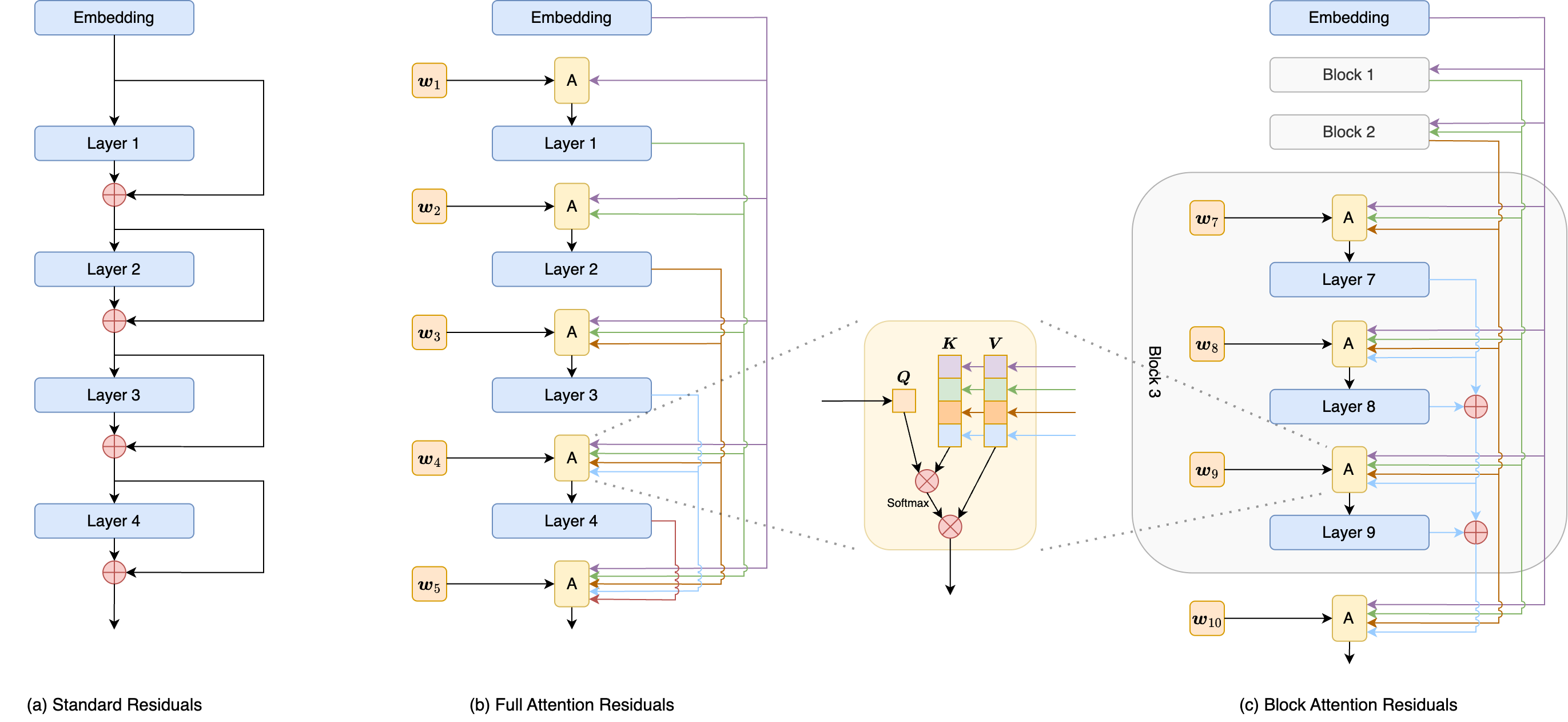
AttnRes示意图
12
Mar
基于流式幂迭代的Muon实现:1. 初识
By 苏剑林 | 2026-03-12 | 5734位读者 | 引用Muon的核心运算是$\newcommand{msign}{\mathop{\text{msign}}}\msign$,当前标准实现是Newton-Schulz迭代。不得不说,这确实是一个非常高效且GPU友好的算法,Muon能流行起来,起码有一大半是这个算法的功劳。然而,这个算法也给人一种“只此一家,别无分号”的感觉,因为它似乎就局限在算$\msign$了,一旦我们想要魔改Muon(比如$\msign$换成这里的$\newcommand{mclip}{\mathop{\text{mclip}}}\mclip$),那么相应的计算就会变得麻烦起来。
本文提出一种新的实现思路——通过流式幂迭代(Streaming Power Iteration)来近似计算SVD。这并不是完全新的思路,而是已经出现之前的一些优化器工作中,但这里我们将它单独提炼出来,作为一个独立的算法使用。
内容回顾
Muon的细节我们就不展开了,大家自行翻看之前的文章如《Muon优化器赏析:从向量到矩阵的本质跨越》、《Muon续集:为什么我们选择尝试Muon?》、《Muon优化器指南:快速上手与关键细节》即可,这里直接给出它的公式:
\begin{equation}\begin{aligned}
\boldsymbol{M}_t =&\, \beta\boldsymbol{M}_{t-1} + \boldsymbol{G}_t \\[5pt]
\boldsymbol{W}_t =&\, \boldsymbol{W}_{t-1} - \eta_t [\msign(\boldsymbol{M}_t) + \lambda \boldsymbol{W}_{t-1}] \\
\end{aligned}\end{equation}
2
Mar
MuP之上:3. 特殊情况特殊处理
By 苏剑林 | 2026-03-02 | 3180位读者 | 引用经过那么多篇相关博客的介绍,想必很多读者都对Muon优化器并不陌生——即便不清楚理论细节,应该也留下了一个“专为矩阵参数定制的优化器”的印象。然而,这个说法并不全对——比如对于输入端的Embedding层和输出段的LM Head来说,它们的参数虽然也都是矩阵,但并不适合用Muon(参考《Muon优化器指南:快速上手与关键细节》)。
为什么它们要被“区别对待”呢?本文将沿用首篇提出的三个稳定性指标,探讨不同类型的层的初始化规律及其对应的最速下降方向,从而回答这个问题。
前情回顾
在第一篇文章《MuP之上:1. 好模型的三个特征》中,我们提出了三个稳定性指标
23
Feb
MoE环游记:7、动态激活极简解
By 苏剑林 | 2026-02-23 | 4844位读者 | 引用上一篇文章《MoE环游记:6、最优分配促均衡》中,我们通过求解如下最优分配问题来实现负载均衡
\begin{equation}\max_{x_{i,j}\in\{0,1\}} \sum_{i,j} x_{i,j}s_{i,j} \qquad\text{s.t.}\qquad \sum_j x_{i,j} = k,\quad \sum_i x_{i,j} = \frac{mk}{n}\end{equation}
其中$\sum_j x_{i,j} = k$表示每个Token恰好激活$k$个Expert,而$\sum_i x_{i,j} = mk/n$表示每个Expert恰好被激活$mk/n$次。然而,仔细思考就会发现,其实前者对训练和推理都不是必要的,我们真正需要的是后者,它意味着“平均来说每个Token激活$k$个Expert”以及每个Expert的负载均衡,这足以达成MoE的目标,所以本文考虑更简化的问题
\begin{equation}\max_{x_{i,j}\in\{0,1\}} \sum_{i,j} x_{i,j}s_{i,j} \qquad\text{s.t.}\qquad \sum_i x_{i,j} = \frac{mk}{n}\label{eq:target-dyn}\end{equation}

最近评论