






26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 63162位读者 |由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率 #
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
下面考虑它们的迁移概率.所谓迁移概率,其实就是条件概率$P(s_2|s_1)$,即当$s_1$出现时后面接$s_2$的概率.通过10万微信文本,我们统计出,“电”字出现的次数为145001,而“电柳”、“电视“、”电规“出现的次数为0、12426、7;“宙”字出现的次数为1980次,而“宙柳”、“宙视”、“宙规”出现的次数为0、0、18,因此,可以算出
$$\begin{array}{l}
\hline
\hline
P(\text{柳}|\text{电})=\frac{0}{145001}=0 \\
P(\text{视}|\text{电})=\frac{12426}{145001}\approx 0.08570 \\
P(\text{规}|\text{电})=\frac{7}{145001}\approx 0.00005 \\
P(\text{柳}|\text{宙})=\frac{0}{1980}=0 \\
P(\text{视}|\text{宙})=\frac{0}{1980}=0 \\
P(\text{规}|\text{宙})=\frac{18}{1980}\approx 0.00909\\
\hline
\hline
\end{array}$$
结果如下图:
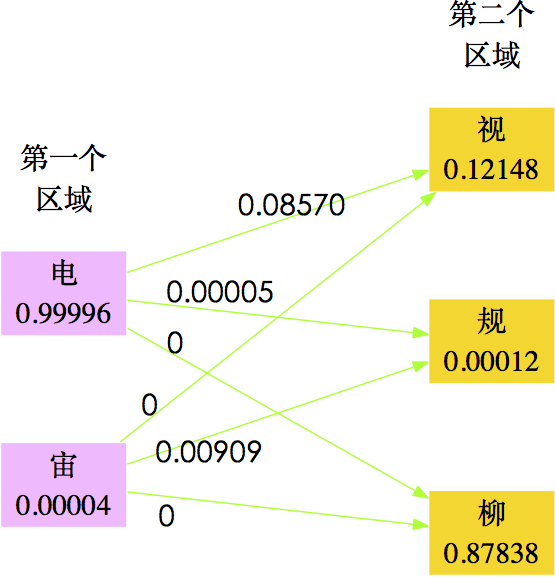
图20 考虑转移概率
从统计的角度来看,最优的$s_1,s_2$组合,应该使得式$(14)$取最大值:
$$f=W(s_1)P(s_2|s_1)W(s_2)\tag{14}$$
因此,可以算得$s_1,s_2$的最佳组合应该是“电视”而不是“电柳”. 这时我们成功地通过统计的方法得到了正确结果,从而提高了正确率.
动态规划 #
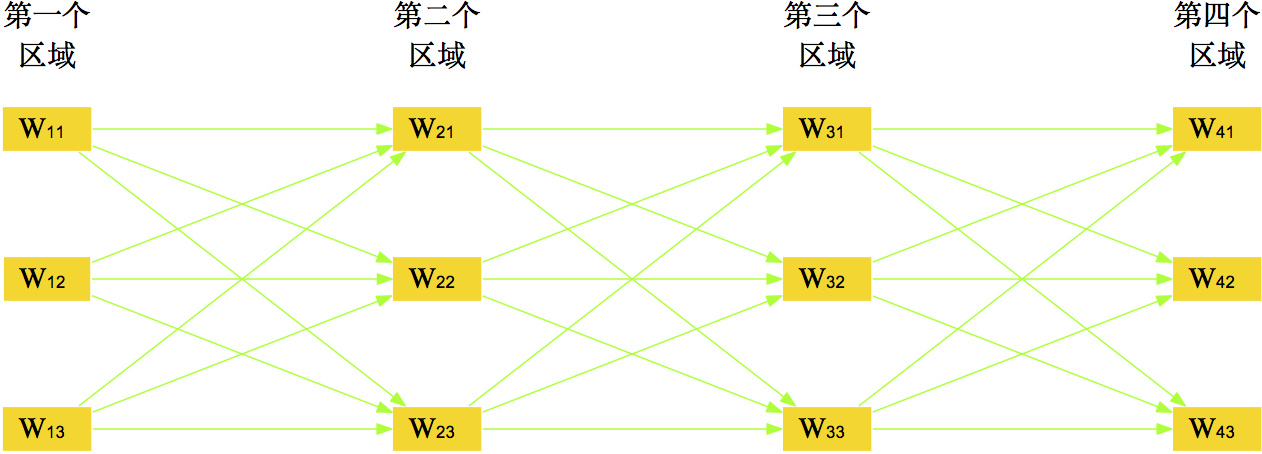
图21 多字图片的规划问题
类似地,如图21,如果一个单行文字图片有$n$个字$s_1,s_2,\dots,s_n$需要确定,那么应当使得
$$f=W(s_1)P(s_2|s_1)W(s_2)P(s_3|s_2)W(s_3)\dots W(s_{n-1})P(s_n|s_{n-1})W(s_n)\tag{15}$$
取得最大值,这就是统计语言模型的思想,自然语言处理的很多领域,比如中文分词、语音识别、图像识别等,都用到了同样的方法[6]. 这里需要解决两个主要的问题:(1)各个$P(s_{i+1}|s_i)$的估计;(2)给定各个$P(s_{i+1}|s_i)$后如何求解$f$的最大值.
转移概率矩阵
对于第一个问题,只需要从大的语料库中统计$s_i$的出现次数$\#s_i$,以及$s_i,s_{i+1}$相接地出现的次数$\#(s_i,s_{i+1})$,然后认为
$$P(s_{i+1}|s_i)=\frac{\#(s_i,s_{i+1})}{\#s_i}\tag{16}$$
即可,本质上没有什么困难. 本文的识别对象有3062个,理论上来说,应该生成一个$3062\times 3062$的矩阵,这是非常庞大的. 当然,这个矩阵是非常稀疏的,我们可以只保存那些有价值的元素.
现在要着重考虑当$\#(s_i,s_{i+1})=0$的情况. 在前一节我们就直接当$P(s_{i+1}|s_i)=0$,但事实上是不合理的. 没有出现不能说明不会出现,只能说明概率很小,因此,即便是对于$\#(s_i,s_{i+1})=0$,也应该赋予一个小概率而不是0. 这在统计上称为数据的平滑问题.
一个简单的平滑方法是在所有项的频数(包括频数为0的项)后面都加上一个正的小常数$\alpha$(比如1),然后重新统计总数并计算频率,这样每个项目都得到了一个正的概率. 这种思路有可能降低高频数的项的概率,但由于这里的概率只具有相对意义,因此这个影响是不明显的(一个更合理的思路是当频数小于某个阈值$T$时才加上常数,其他不加. ). 按照这种思路,从数十万微信文章中,我们计算得到了160万的邻接汉字的转移概率矩阵.
Viterbi算法
对于第二个问题,求解最优组合$s_1,s_2,\dots,s_n$是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6].
Viterbi算法是一个简单高效的算法,用Python实现也就十来行的代码. 它的核心思想是:如果最终的最优路径经过某个$s_{i-1}$,那么从初始节点到$s_{i-1}$点的路径必然也是一个最优路径——因为每一个节点$s_i$只会影响前后两个$P(s_i|s_{i-1})$和$P(s_{i+1}|s_i)$.
根据这个思想,可以通过递推的方法,在考虑每个$s_i$时只需要求出所有经过各$s_{i-1}$的候选点的最优路径,然后再与当前的$s_i$结合比较. 这样每步只需要算不超过$l^2$次,就可以逐步找出最优路径. Viterbi算法的效率是$\mathcal{O}(n\cdot l^2)$,$l$是候选数目最多的节点$s_i$的候选数目,它正比于$n$,这是非常高效率的.
提升效果 #
实验表明,结合统计语言模型进行动态规划能够很好地解决部分形近字识别错误的情况. 在我们的测试中,它能修正一些错误如下:
$$\begin{array}{c}
\hline
\hline
\text{电柳} \quad \to \quad \text{电视}\\
\text{研友} \quad \to \quad \text{研发}\\
\text{速于} \quad \to \quad \text{速干}\\
\text{围像} \quad \to \quad \text{图像}\\
\dots\\
\hline
\hline
\end{array}\\
$$
由于用来生成转移矩阵的语料库不够大,因此修正的效果还有很大的提升空间. 不管怎么说,由于Viterbi算法的简单高效,这是一个性价比很高的步骤.
转载到请包括本文地址:https://www.kexue.fm/archives/3842
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 26, 2016). 《OCR技术浅探:7. 语言模型 》[Blog post]. Retrieved from https://www.kexue.fm/archives/3842
@online{kexuefm-3842,
title={OCR技术浅探:7. 语言模型},
author={苏剑林},
year={2016},
month={Jun},
url={\url{https://www.kexue.fm/archives/3842}},
}

September 21st, 2016
条件概率的计算反了吧, p(a|b) = p(ab)/p(b)
April 18th, 2018
[...]OCR技术浅探:7. 语言模型[...]
August 2nd, 2018
本人即将大三,最近也在搞OCR的东西,最近的一个比赛,PAC并行计算的人工智能组。和百度西交大的数据相比,这次的数据简直,嗯。。。。无话可说。前期预处理的工作难度很大,前期的预处理尝试了常见的东西,比如边缘检测、灰度化、二值化、开闭操作等,然后导入CNN去训练,效果不是很好,应该说是很烂。。看了你的OCR的博客,似乎受了点启发,比如放弃那种预处理的方式,emmmm,等我做完了再来交流。
欢迎试用交流哈~
April 16th, 2020
苏神,我也正在利用语言模型来优化OCR的识别结果,我有一个问题想探讨一下,你的转移概率那部分中公式(15)我感觉像是BiGram的语言模型(若理解有偏差请纠正我),我现在若想使用3Gram的语言模型,维特比算最短路径那里是不是需要回溯两步,然后前两步的候选词的组合中最高的概率,并存下这个组合的两个index?这里我没有怎么想明白,请苏神指教
的确是BiGram,至于3Gram,我也没经验(捂脸)
November 17th, 2022
[...]OCR技术浅探:7. 语言模型[...]
November 17th, 2022
[...]OCR技术浅探:7. 语言模型[...]
April 1st, 2023
[...]OCR技术浅探:7. 语言模型[...]