






7
Mar
Tiger:一个“抠”到极致的优化器
By 苏剑林 | 2023-03-07 | 75027位读者 |这段时间笔者一直在实验《Google新搜出的优化器Lion:效率与效果兼得的“训练狮”》所介绍的Lion优化器。之所以对Lion饶有兴致,是因为它跟笔者之前的关于理想优化器的一些想法不谋而合,但当时笔者没有调出好的效果,而Lion则做好了。
相比标准的Lion,笔者更感兴趣的是它在$\beta_1=\beta_2$时的特殊例子,这里称之为“Tiger”。Tiger只用到了动量来构建更新量,根据《隐藏在动量中的梯度累积:少更新几步,效果反而更好?》的结论,此时我们不新增一组参数来“无感”地实现梯度累积!这也意味着在我们有梯度累积需求时,Tiger已经达到了显存占用的最优解,这也是“Tiger”这个名字的来源(Tight-fisted Optimizer,抠门的优化器,不舍得多花一点显存)。
此外,Tiger还加入了我们的一些超参数调节经验,以及提出了一个防止模型出现NaN(尤其是混合精度训练下)的简单策略。我们的初步实验显示,Tiger的这些改动,能够更加友好地完成模型(尤其是大模型)的训练。
基本形式 #
Tiger的更新规则为
\begin{equation}\text{Tiger}:=\left\{\begin{aligned}
&\boldsymbol{m}_t = \beta \boldsymbol{m}_{t-1} + \left(1 - \beta\right) \boldsymbol{g}_t \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t \left[\text{sign}(\boldsymbol{m}_t) \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}\right] \\
\end{aligned}\right.\end{equation}
相比Lion,它就是选择了参数$\beta_1 = \beta_2 = \beta$;相比SignSGD,它则是新增了动量和权重衰减。
参考实现:
下表对比了Tiger、Lion和AdamW的更新规则:
\begin{array}{c|c|c}
\hline
\text{Tiger} & \text{Lion} & \text{AdamW} \\
\hline
{\begin{aligned}
&\boldsymbol{m}_t = \beta \boldsymbol{m}_{t-1} + \left(1 - \beta\right) \boldsymbol{g}_t \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t \left[\text{sign}(\boldsymbol{m}_t) \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}\right] \\
\end{aligned}} &
{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}} &
{\begin{aligned}
&\boldsymbol{m}_t = \beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\\
&\boldsymbol{v}_t = \beta_2 \boldsymbol{v}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t^2\\
&\hat{\boldsymbol{m}}_t = \boldsymbol{m}_t\left/\left(1 - \beta_1^t\right)\right.\\
&\hat{\boldsymbol{v}}_t = \boldsymbol{v}_t\left/\left(1 - \beta_2^t\right)\right.\\
&\boldsymbol{u}_t =\hat{\boldsymbol{m}}_t\left/\left(\sqrt{\hat{\boldsymbol{v}}_t} + \epsilon\right)\right.\\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}})
\end{aligned}} \\
\hline
\end{array}
可见Tiger是三者之中的极简者。
超参设置 #
尽管Tiger已经相当简化,但仍有几个超参数要设置,分别是滑动平均率$\beta$、学习率$\eta_t$以及权重衰减率$\lambda_t$,下面我们分别讨论这几个参数的选择。
滑动率 #
比较简单的是滑动平均的衰减率$\beta$。我们知道,在基本形式上Tiger相当于Lion取$\beta_1 = \beta_2 = \beta$的特殊情形,那么一个直觉是Tiger应当取$\beta=\frac{1}{2}(\beta_1 + \beta_2)$。在Lion的原论文中,对于CV任务有$\beta_1=0.9,\beta_2=0.99$,所以我们建议CV任务取$\beta = 0.945$;而对于NLP任务则有$\beta_1=0.95,\beta_2=0.98$,所以我们建议NLP任务取$\beta = 0.965$。
学习率 #
对于学习率,Tiger参考了Amos、LAMB等工作,将学习率分两种情况设置。第一种是线性层的bias项和Normalization的beta、gamma参数,这类参数的特点是运算是element-wise,我们建议学习率选取为全局相对学习率$\alpha_t$的一半;第二种主要就是线性层的kernel矩阵,这类参数的特点是以矩阵的身份去跟向量做矩阵乘法运算,我们建议学习率选取为全局相对学习率$\alpha_t$乘以参数本身的$\text{RMS}$(Root Mean Square):
\begin{equation}\eta_t = \left\{\begin{aligned}
&\alpha_t \times 0.5, &\boldsymbol{\theta} \in \{bias, beta, gamma\}\\[5pt]
&\alpha_t \times \text{RMS}(\boldsymbol{\theta}_{t-1}), &\boldsymbol{\theta} \not\in \{bias, beta, gamma\}
\end{aligned}\right.\end{equation}
其中
\begin{equation}\text{RMS}(\boldsymbol{\theta})=\sqrt{\frac{1}{k}\sum_{i=1}^k \theta_i^2},\quad \boldsymbol{\theta}=(\theta_1,\theta_2,\cdots,\theta_k)\end{equation}
这样设置的好处是我们把参数的尺度分离了出来,使得学习率的调控可以交给一个比较通用的“全局相对学习率”$\alpha_t$——大致可以理解为每一步的相对学习幅度,是一个对于模型尺度不是特别敏感的量。
换句话说,我们在base版模型上调好的$\alpha_t$,基本上可以不改动地用到large版模型。注意$\alpha_t$带有下标$t$,所以它包含了整个学习率的schedule,包括Wamrup以及学习率衰减策略等,笔者的设置经验是$\max(\alpha_t)\in[0.001,0.002]$,至于怎么Warmup和衰减,那就是大家根据自己的任务而设了,别人无法代劳。笔者给的tiger实现,内置了一个分段线性学习率策略,理论上可以用它模拟任意的$\alpha_t$。
衰减率 #
最后是权重衰减率$\lambda_t$,这个Lion论文最后一页也给出了一些参考设置,一般来说$\lambda_t$也就设为常数,笔者常用的是0.01。特别的是,不建议对前面说的bias、beta、gamma这三类参数做权重衰减,或者即便要做,$\lambda_t$也要低一个数量级以上。因为从先验分布角度来看,权重衰减是参数的高斯先验,$\lambda_t$跟参数方差是反比关系,而bias、beta、gamma的方差显然要比kernel矩阵的方差大,所以它们的$\lambda_t$应该更小。
\begin{equation}\lambda_t = \left\{\begin{aligned}
&0, &\boldsymbol{\theta} \in \{bias, beta, gamma\}\\[5pt]
&constant > 0, &\boldsymbol{\theta} \not\in \{bias, beta, gamma\}
\end{aligned}\right.\end{equation}
梯度累积 #
对于很多算力有限的读者来说,通过梯度累积来增大batch_size是训练大模型时不可避免的一步。标准的梯度累积需要新增一组参数,用来缓存历史梯度,这意味着在梯度累积的需求下,Adam新增的参数是3组,Lion是2组,而即便是不加动量的AdaFactor也有1.x组(但说实话AdaFactor不加动量,收敛会慢很多,所以考虑速度的话,加一组动量就变为2.x组)。
而对于Tiger来说,它的更新量只用到了动量和原参数,根据《隐藏在动量中的梯度累积:少更新几步,效果反而更好?》,我们可以通过如下改动,将梯度累积内置在Tiger中:
\begin{equation}\text{Tiger}:=\left\{\begin{aligned} &\boldsymbol{m}_t = \big[(\beta - 1)\chi_{(t-1)/k} + 1\big] \boldsymbol{m}_{t-1} + \frac{1}{k}\left(1 - \beta\right) \boldsymbol{g}_t \\ &\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \chi_{t/k}\eta_t \left[\text{sign}(\boldsymbol{m}_t) \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}\right] \\ \end{aligned}\right.\end{equation}
这里的$\chi_{t/k}$是判断$t$能否被$k$整除的示性函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
可以看到,这仅仅相当于修改了滑动平均率$\beta$和学习率$\eta_t$,几乎不增加显存成本,整个过程是完全“无感”的,这是笔者认为的Tiger的最大的魅力。
需要指出的是,尽管Lion跟Tiger很相似,但是Lion并不能做到这一点,因为$\beta_1\neq\beta_2$时,Lion的更新需要用到动量以及当前批的梯度,这两个量需要用不同的参数缓存,而Tiger的更新只用到了动量,因此满足这一点。类似滴,SGDM优化器也能做到一点,但是它没有$\text{sign}$操作,这意味着学习率的自适应能力不够好,在Transformer等模型上的效果通常不如意(参考《Why are Adaptive Methods Good for Attention Models?》)。
全半精度 #
对于大模型来说,混合精度训练是另一个常用的“利器”(参考《在bert4keras中使用混合精度和XLA加速训练》)。混合精度,简单来说就是模型计算部分用半精度的FP16,模型参数的储存和更新部分用单精度的FP32。之所以模型参数要用FP32,是因为担心更新过程中参数的更新量过小,下溢出了FP16的表示范围(大致是$6\times 10^{-8}\sim 65504$),导致某些参数长期不更新,模型训练进度慢甚至无法正常训练。
然而,Tiger(Lion也一样)对更新量做了$\text{sign}$运算,这使得理论上我们可以全用半精度训练!分析过程并不难。首先,只要对Loss做适当的缩放,那么可以做到梯度$\boldsymbol{g}_t$不会溢出FP16的表示范围;而动量$\boldsymbol{m}_t$只是梯度的滑动平均,梯度不溢出,它也不会溢出,$\text{sign}(\boldsymbol{m}_t)$只能是$\pm 1$,更加不会溢出了;之后,我们只需要保证学习率不小于$6\times 10^{-8}$,那么更新量就不会下溢了,事实上我们也不会将学习率调得这么小。因此,Tiger的整个更新过程都是在FP16表示范围内的,因此理论上我们可以直接用全FP16精度训练而不用担心溢出问题。
防止NaN #
然而,笔者发现对于同样的配置,在FP32下训练正常,但切换到混合精度或者半精度后有时会训练失败,具体表现后Loss先降后升然后NaN,这我们之前在《在bert4keras中使用混合精度和XLA加速训练》也讨论过。虽然有一些排查改进的方向(比如调节epsilon和无穷大的值、缩放loss等),但有时候把该排查的都排查了,还会出现这样的情况。
经过调试,笔者发现出现这种情况时,主要是对于某些batch梯度变为NaN,但此时模型的参数和前向计算还是正常的。于是笔者就想了个简单的应对策略:对梯度出现NaN时,跳过这一步更新,并且对参数进行轻微收缩,如下
\begin{equation}\text{Tiger}:=\left\{\begin{aligned}
&\boldsymbol{m}_t = \boldsymbol{m}_{t-1} \\
&\boldsymbol{\theta}_t = (\boldsymbol{\theta}_{t-1} - c)\times s+ c \\
\end{aligned}\right. \quad if\,\,\boldsymbol{g}_t = \text{NaN}\end{equation}
其中$s\in(0, 1)$代表收缩率,笔者取$s=0.99$,$c$则是参数的初始化中心,一般就是gamma取1,其他参数都是0。经过这样处理后,模型的loss会有轻微上升,但一般能够恢复正常训练,不至于从头再来。个人的实验结果显示,这样处理能够缓解一部分NaN的问题。
当然,该技巧一般的使用场景是同样配置下FP32能够正常训练,并且已经做好了epsilon、无穷大等混合精度调节,万般无奈之下才不得已使用的。如果模型本身超参数设置有问题(比如学习率过大),连FP32都会训练到NaN,那么就不要指望这个技巧能够解决问题了。此外,有兴趣的读者,还可以尝试改进这个技巧,比如收缩之后可以再加上一点噪声来增加参数的多样性,等等。
实验结果 #
不考虑梯度累积带来的显存优化,Tiger就是Lion的一个特例,可以预估Tiger的最佳效果肯定是不如Lion的最佳效果的,那么效果下降的幅度是否在可接受范围内呢?综合到目前为止多方的实验结果,笔者暂时得出的结论是:
$$\begin{aligned}
&\text{效果}\color{red}{(\uparrow)}\text{:}\quad\text{Lion} \geq \text{Tiger} \geq \text{AdamW} \approx \text{LAMB} \\
&\text{显存}\color{red}{(\downarrow)}\text{:}\quad\text{Tiger} < \text{Lion} < \text{AdamW} = \text{LAMB} \\
\end{aligned}$$
也就是说,考虑效果Lion最优,考虑显存占用Tiger最优(启用梯度累积时),效果上Tiger不逊色于AdamW,所以Tiger替代AdamW时没有太大问题的。
具体实验结果包括几部分。第一部分实验来自Lion的论文《Symbolic Discovery of Optimization Algorithms》,论文中的Figure 12对比了Lion、Tiger、AdamW在不同尺寸的语言模型上的效果:
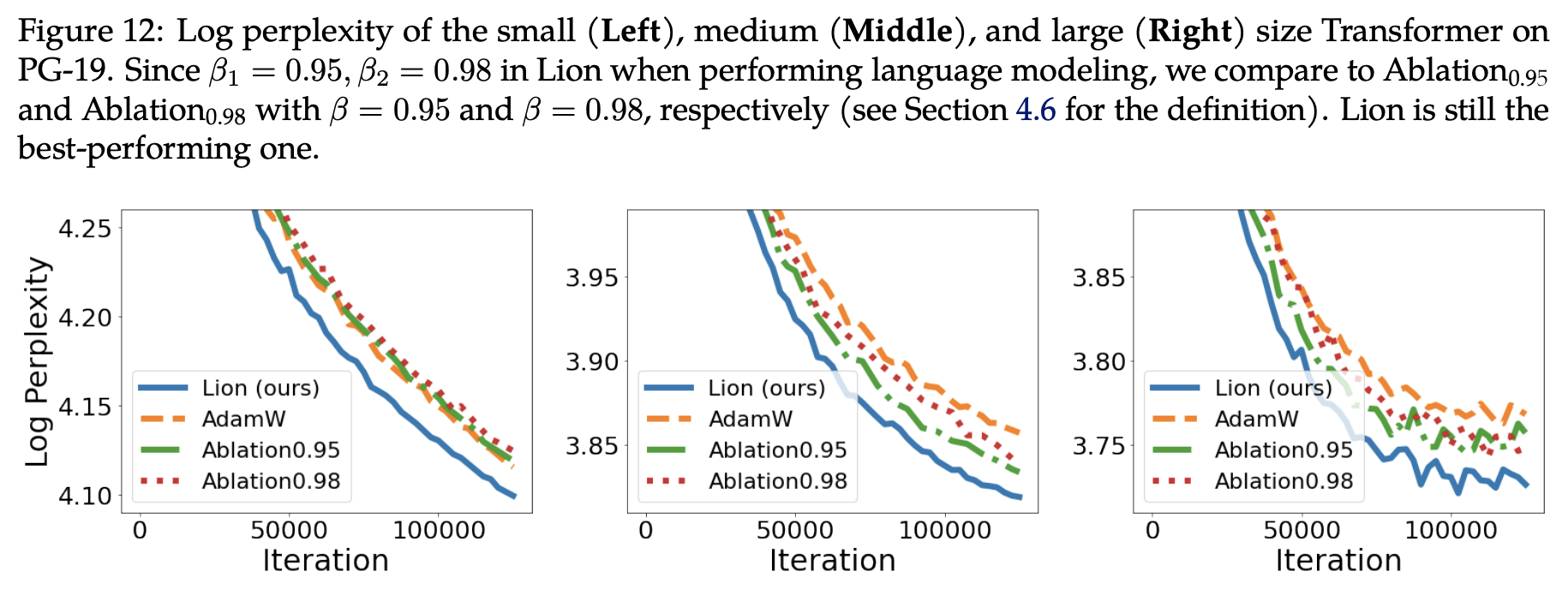
Lion、Tiger(Ablation)、AdamW在语言模型任务上的对比
这里的Ablation0.95、Ablation0.98,就是Tiger的$\beta$分别取0.95、0.98。可以看到,对于small级别模型,两个Tiger持平AdamW,而在middle和large级别上,两个Tiger都超过了AdamW。但正如前面所说,$\beta$取两者的均值0.965,有可能还会有进一步的提升。
至于在CV任务上,原论文给出了Table 7:
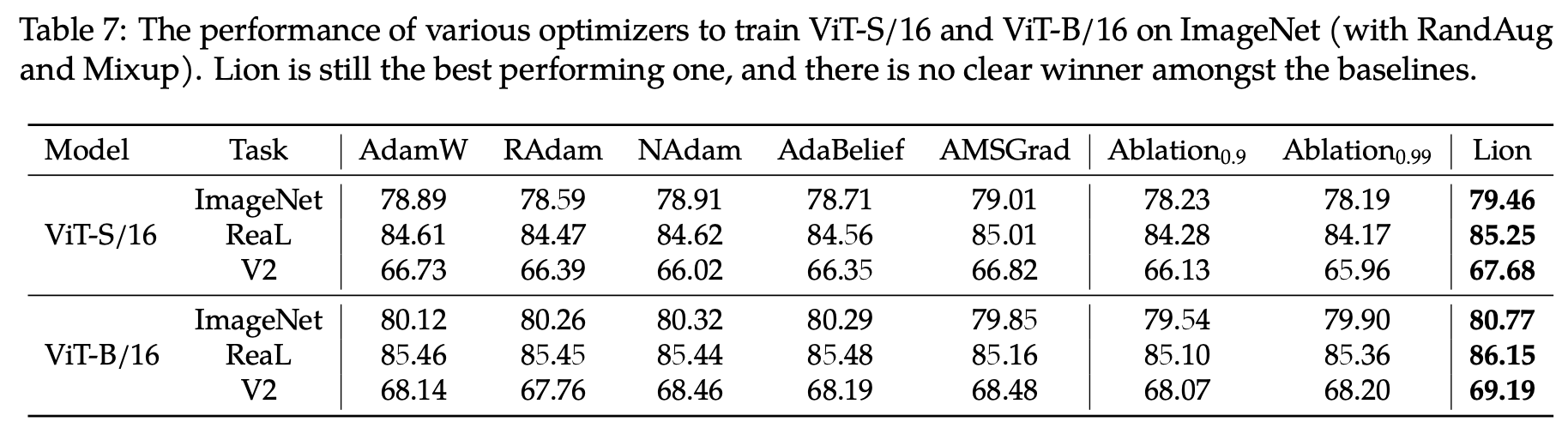
Lion、Tiger(Ablation)、AdamW在图像分类任务上的对比
同样地,这里的Ablation0.9、Ablation0.99,就是Tiger的$\beta$分别取0.9、0.99。在这个表中,Tiger跟AdamW有明显差距。但是考虑到作者只实验了0.9、0.99两个$\beta$,而笔者推荐的是$\beta=0.945$,所以笔者跟原作者取得了联系,请他们做了补充实验,他们回复的结果是“$\beta$分别取0.92、0.95、0.98时,在ViT-B/16上ImageNet的结果都是80.0%左右”,那么对比上图,就可以确定在精调$\beta$时,在CV任务上Tiger应该也可以追平AdamW的。
最后是笔者自己的实验。笔者常用的是LAMB优化器,它的效果基本跟AdamW持平,但相对更稳定,而且对不同的初始化适应性更好,因此笔者更乐意使用LAMB。特别地,LAMB的学习率设置可以完全不改动地搬到Tiger中。笔者用Tiger重新训练了之前的base版GAU-α模型,训练曲线跟之前的对比如下:

笔者在GAU-α上的对比实验(loss曲线)

笔者在GAU-α上的对比实验(accuracy曲线)
可以看到,Tiger确实可以取得比LAMB更优异的表现。
未来工作 #
Tiger还有改进空间吗?肯定有,想法其实有很多,但都没来得及一一验证,大家有兴趣的可以帮忙继续做下去。
在《Google新搜出的优化器Lion:效率与效果兼得的“训练狮”》中,笔者对$\text{sign}$运算的评价是
Lion通过$\text{sign}$操作平等地对待了每一个分量,使得模型充分地发挥了每一个分量的作用,从而有更好的泛化性能。如果是SGD,那么更新的大小正比于它的梯度,然而有些分量梯度小,可能仅仅是因为它没初始化好,而并非它不重要,所以Lion的$\text{sign}$操作算是为每个参数都提供了“恢复活力”甚至“再创辉煌”的机会。
然而,细思之下就会发现,这里其实有一个改进空间。“平等地对待了每一个分量”在训练的开始阶段是很合理的,它保留了模型尽可能多的可能。然而,如果一个参数长时间的梯度都很小,那么很有可能这个参数真的是“烂泥扶不上墙”,即已经优化到尽头了,这时候如果还是“平等地对待了每一个分量”,那么就对那些梯度依然较大的“上进生”分量不公平了,而且很可能导致模型震荡。
一个符合直觉的想法是,优化器应该随着训练的推进,慢慢从Tiger退化为SGD。为此,我们可以考虑将更新量设置为
\begin{equation}\boldsymbol{u}_t = \text{sign}(\boldsymbol{m}_t) \times |\boldsymbol{m}_t|^{1-\gamma_t}\end{equation}
这里的绝对值和幂运算都是element-wise的,$\gamma_t$是从1到0的单调递减函数,当$\gamma_t=1$时对应Tiger,当$\gamma_t = 0$时对应SGDM。
可能读者会吐槽这里多了$\gamma_t$这个schedule要调整,问题变得复杂很多。确实如此,如果将它独立地进行调参,那么确实会引入过多的复杂度了。但我们不妨再仔细回忆一下,抛开Warmup阶段不算,一般情况下相对学习率$\alpha_t$不正是一个单调递减至零的函数?我们是否可以借助$\alpha_t$来设计$\gamma_t$呢?比如$\alpha_t/\alpha_0$不正好是一个从1到0的单调递减函数?能否用它来作为$\gamma_t$?当然也有可能是$(\alpha_t/\alpha_0)^2$、$\sqrt{\alpha_t/\alpha_0}$更好,调参空间还是有的,但至少我们不用重新设计横跨整个训练进程的schedule了。
更发散一些,既然有时候学习率我们也可以用非单调的schedule(比如带restart的cosine annealing),那么$\gamma_t$我们是否也可以用非单调的(相当于Tiger、SGDM反复切换)?这些想法都有待验证。
文章小结 #
在这篇文章中,我们提出了一个新的优化器,名为Tiger(Tight-fisted Optimizer,抠门的优化器),它在Lion的基础上做了一些简化,并加入了我们的一些超参数经验。特别地,在需要梯度累积的场景下,Tiger可以达到显存占用的理论最优(抠)解!
转载到请包括本文地址:https://www.kexue.fm/archives/9512
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 07, 2023). 《Tiger:一个“抠”到极致的优化器 》[Blog post]. Retrieved from https://www.kexue.fm/archives/9512
@online{kexuefm-9512,
title={Tiger:一个“抠”到极致的优化器},
author={苏剑林},
year={2023},
month={Mar},
url={\url{https://www.kexue.fm/archives/9512}},
}

March 7th, 2023
感谢苏神!我通过可视化对比了Lion与Adam优化器,可以看到Lion优化器趋向于在大范围进行搜索解空间以后再进行小范围搜索,与adam不同,adam趋向于直接使用小范围局部的梯度直接走向局部最小值,此外SGD也有类似的表现,而SIGNUM则与Lion相近,但是由于其没有衰减系数,无法快速的锁定大致范围。此外Lion优化器必须搭配学习率衰减。
我将再次更新,画出Tiger作为对比。
github地址:https://github.com/nengwp/Lion-vs-Adam
Tiger跟Lion的训练曲线应该不会有太大区别,Tiger的更新重点主要是无感的梯度累积以及学习率本身的一些调整(捂脸)。
March 7th, 2023
式(2)中每一步都要计算RMS,这一步会不会花费很多时间?
相比训练其他部分,RMS计算还是很快的。如果实在有强迫症,可以将它替换为为$1/\sqrt{d}$,$d$是hidden_size。
March 7th, 2023
(以下讨论限于PyTorch框架)
实验效果很棒,但突然又想到在实践中这么做梯度累积似乎做不到“完全”无感(捂脸)
我理解这里的无感的意思是,不需要对训练循环中做修改。
但在一般的梯度累积中使用多卡训练时,对于不需要更新模型参数的step,可以让各GPU之间不做同步,需要更新模型参数时,再在多卡之间同步梯度,以省去IO开销;这个步骤optimizer没法控制。
所以要梯度累积时,可能还是需要加一些控制代码
PyTorch框架据说可以无成本实现梯度累积,这个我不熟悉,不过多评价。
但是你提的这个需求,跟Tiger的改动应该是两个不同的问题。按照我的理解,即便我们可以实现在需要更新参数时再在多卡之间同步梯度,但单卡之内仍然需要新建一组变量来缓存单卡的累积梯度。
嗯,的确是两个不同的问题
March 7th, 2023
老师有推荐的数学博客吗?需要科学上网的也可以
抱歉,没有。
March 14th, 2023
不知道为啥,Lion这个优化器在分类和自然语言上效果还不错,但是分割任务差了很多,有时基本不起作用
视觉上的任务我没啥经验啊,Lion原论文好像也没做分割任务,结论不大清楚。如果你有兴趣,可以邮件联系作者讨论看看。我跟作者联系过,他们还是很乐意交流的。
April 24th, 2023
苏神,这个Tiger和Lion用cuda写的话,其实没有啥速度区别的吧,显存是完全没区别的。
按照我的理解,在tf或者jax下,如果有梯度累积需求,那么显存是有区别的。
May 30th, 2023
最近又新出了一个Sophia优化器
看到了。主要是它包含了二阶梯度,我不大喜欢。
August 28th, 2023
[...]打从在《Tiger:一个“抠”到极致的优化器》提出了Tiger优化器之后,Tiger就一直成为了我训练模型的“标配”优化器。最近笔者已经尝试将Tiger用到了70亿参数模型的预训练之中,前期效果看上来尚可,初步说明Tiger也是能Scale Up的。不过,在查看训练好的模型权重时,笔者发现Embedding出现了一些异常值,有些Embedding的分量达到了$pm 100$的级别。[...]
December 4th, 2023
我最近也碰到了NaN的问题,感谢解答。
December 30th, 2024
苏神,数值下溢部分的分析可能有一点没有考虑到,除了小于表示范围下界,由于现在常用BF16训练,会存在catastrophic cancellation问题,即BF16大参数+小更新量导致更新量被cancel。所以可能还是需要用FP32表示master weights。具体可以参考Gopher论文的BF16训练部分。
嗯,自己写的话,优化器的states和weights都是fp32的。