






25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 92024位读者 |经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择 #
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.
训练数据 #
为了训练一个良好的模型,必须有足够多的训练数据. 幸运的是,虽然没有现成的数据可以用,但是由于我们只是做印刷字体的识别,因此,我们可以使用计算机自动生成一批训练数据. 通过以下步骤,我们构建了一批比较充分的训练数据:
1. 更多细节 由于汉字的结构比数字和英文都要复杂,因此,为了体现更多的细节信息,我使用$48\times 48$的灰度图像构建样本,作为模型的输入;
2. 常见汉字 为了保证模型的实用性,我们从网络爬取了数十万篇微信公众平台上的文章,然后合并起来统计各自的频率,最后选出了频率最高的3000个汉字(在本文中我们只考虑简体字),并且加上26个字母(大小写)和10个数字,共3062字作为模型的输出;
3. 数据充分 我们人工收集了45种不同的字体,从正规的宋体、黑体、楷体到不规范的手写体都有,基本上能够比较全面地覆盖各种印刷字体;
4. 人工噪音 每种字体都构建了5种不同字号(46到50)的图片,每种字号2张,并且为了增强模型的泛化能力,将每个样本都加上5%的随机噪音.
经过上述步骤,我们一共生成了$3062\times 45\times 5\times 2=1377900$个样本作为训练样本,可见数据量是足够充分的.
模型结构 #
在模型结构方面,有一些前人的工作可以参考的. 一个类似的例子是MNIST手写数字的识别——它往往作为一个新的图像识别模型的“试金石”——是要将六万多张大小为$28\times 28$像素的手写数字图像进行识别,这个案例跟我们实现汉字的识别系统具有一定的相似性,因此在模型的结构方面可以借鉴. 一个常见的通过卷积神经网络对MNIST手写数字进行识别的模型结构如图
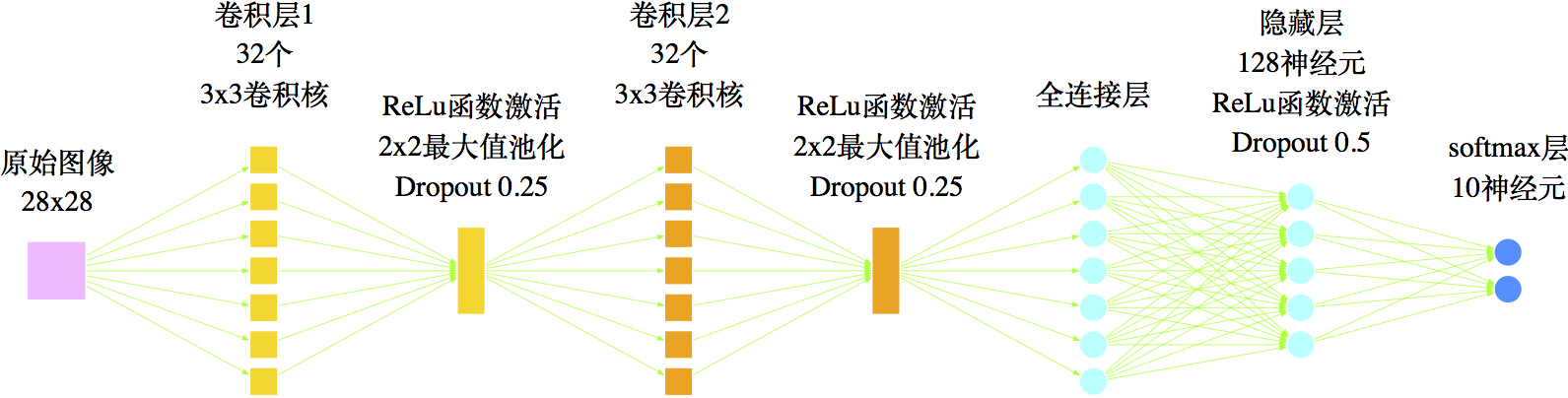
图17 一个用作MNIST手写数字识别的网络结构
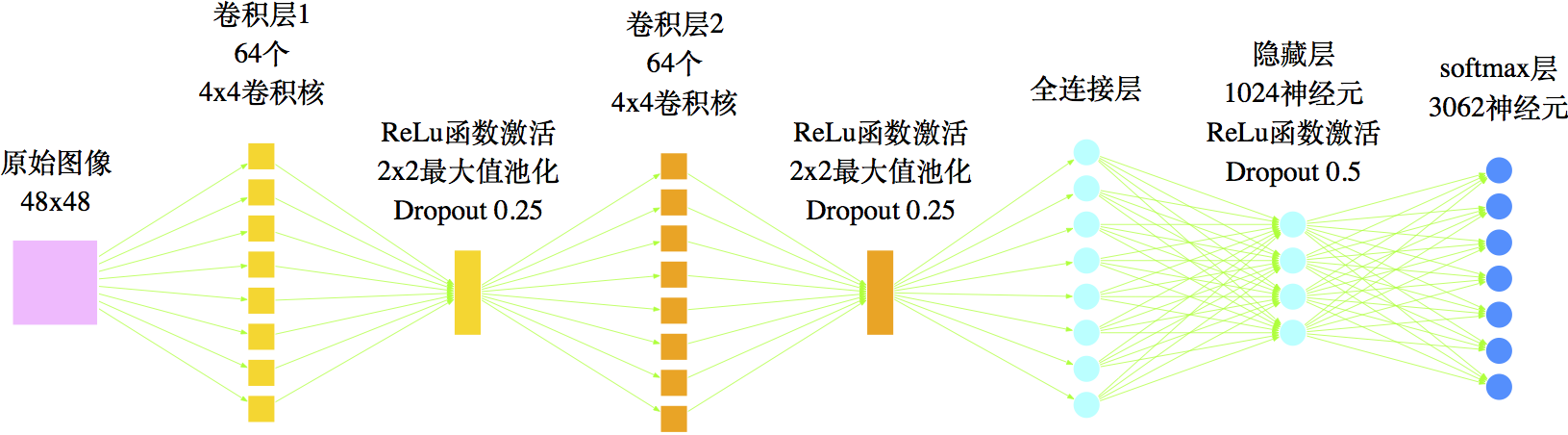
图18 本文用来识别印刷汉字的网络结构
经过充分训练后,如图17的网络结构可以达到99%以上的精确度,说明这种结构确实是可取的. 但是很显然,手写数字不过只有10个,而常用汉字具有数千个,在本文的分类任务中,就共有3062个目标. 也就是说,汉字具有更为复杂和精细的结构,因此模型的各方面都要进行调整. 首先,在模型的输入方面,我们已经将图像的大小从28x28提高为48x48,这能保留更多的细节,其次,在模型结构上要复杂化调整,包括:增加卷积核的数目,增加隐藏节点的数目、调整权重等. 最终我们的网络结构如图18.
在激活函数方面,我们选取了ReLu函数为激活函数
$$ReLu(x)=\left\{\begin{aligned}&x,\quad x>0\\
&0,\quad x\leq 0\end{aligned}\right.\tag{13}$$
实验表明,它相比于传统的sigmoid、tanh等激活函数,能够大大地提升模型效果[3][4];在防止过拟合方面,我们使用了深度学习网络中最常用的Dropout方式[5],即随机地让部分神经元休眠,这等价于同时训练多个不同网络,从而防止了部分节点可能出现的过拟合现象.
需要指出的是,在模型结构方面,我们事实上做了大量的筛选工作.比如隐藏层神经元的数目,我们就耗费了若干天时间,尝试了512、1024、2048、4096、8192等数目,最终得到1024这个比较适合的值.数目太多则导致模型太庞大,而且容易过拟合;太少则容易欠拟合,效果不好.我们的测试发现,从512到1024,效果有明显提升;而再增加节点效果没有明显提升,有时还会有明显下降.
模型实现 #
我们的模型在操作系统为CentOS 7的服务器(24核CPU+96G内存+GTX960显卡)下完成,使用Python 2.7编写代码,并且使用Keras作为深度学习库,用Theano作为GPU加速库(Tensorflow一直提示内存溢出,配置不成功. ).
在训练算法方面,使用了Adam优化方法进行训练,batch size为1024,迭代30次,迭代一次大约需要700秒.
如果出现形近字时,应该是高频字更有可能,最典型的例子就是“日”、“曰”了,这两个的特征是很相似的,但是“日”出现的频率远高于“曰”,因此,应当优先考虑“日”. 因此,在训练模型的时候,我们还对模型最终的损失函数进行了调整,使得高频字的权重更大,这样能够提升模型的预测性能.
经过多次调试,最终得到了一个比较可靠的模型. 模型的收敛过程如下图.
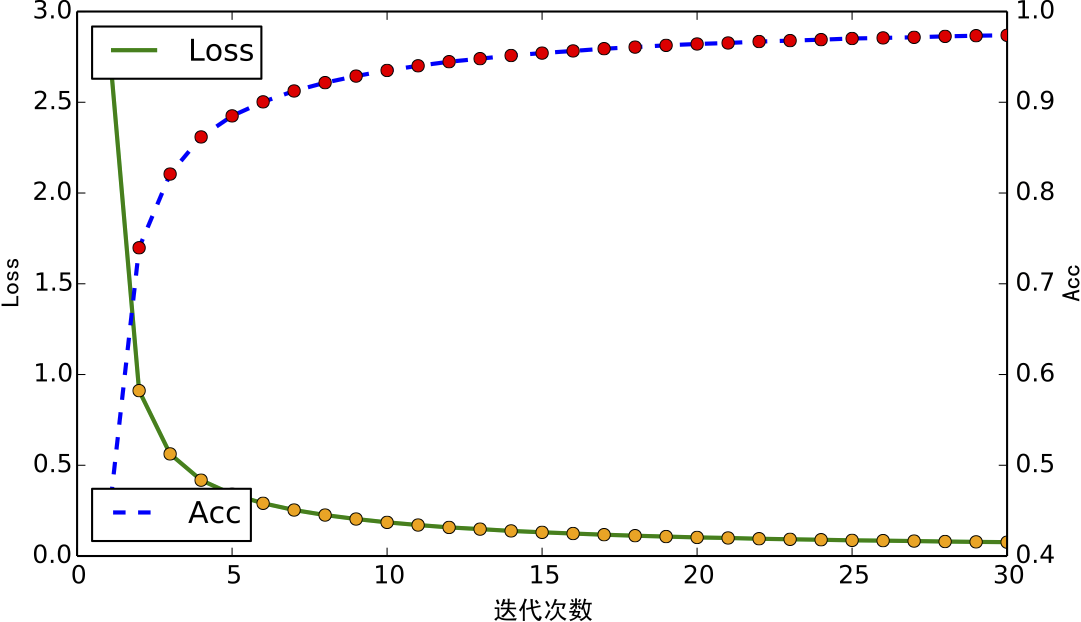
训练曲线图:Loss(损失函数)和Acc(精度)
模型检验 #
我们将从以下三个方面对模型进行检验. 实验结果表明,对于单字的识别效果,我们的模型优于Google开源的OCR系统Tesseract.
训练集检验
最终训练出来的模型,在训练集的检验报告如表1.
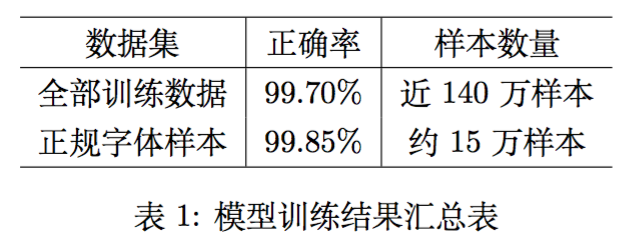
模型训练结果汇总表
从表1可以看到,即便在加入了随机噪音的样本中,模型的正确率仍然有99.7%,因此,我们有把握地说,单纯从单字识别这部分来看,我们的结果已经达到了state of the art级别,而且在黑体、宋体等正规字体中(正规字体样本是指所有训练样本中,字体为黑体、宋体、楷体、微软雅黑和Arial unicode MS的训练样本,这几种字体常见于印刷体中.),正确率更加高!
测试集检验
我们另外挑选了5种字体,根据同样的方法生成了一批测试样本(每种字体30620张,共153100张),用来对模型进行测试,得到模型测试正确率为92.11%. 五种字体的测试结果如表2.

模型在测试集中的结果(5%的随机噪音)
从表中可以看出,即便是对于训练集之外的样本,模型效果也相当不错.接着,我们将随机噪音增大到15%(这对于一张$48\times 48$的文字图片来说已经相当糟糕了),得到的测试结果如表3.

模型在测试集中的结果(15%的随机噪音)
平均的正确率为87.59%,也就是说,噪音的影响并不明显,模型能够保持90%左右的正确率. 这说明该模型已经完全达到了实用的程度.
转载到请包括本文地址:https://www.kexue.fm/archives/3831
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 25, 2016). 《OCR技术浅探:6. 光学识别 》[Blog post]. Retrieved from https://www.kexue.fm/archives/3831
@online{kexuefm-3831,
title={OCR技术浅探:6. 光学识别},
author={苏剑林},
year={2016},
month={Jun},
url={\url{https://www.kexue.fm/archives/3831}},
}

September 7th, 2016
hi 你好,看了你的文章,很受启发,想跟你了解一下,ocr.py里的zhuanyi.csv是什么呢,能否公布一下呢?还有,一个小建议,代码是否可以提交到github呢,这样能有更多人受益呢,再次感谢你的大作。
zhuanyi.csv是统计出来的转移矩阵,也就是语言模型。
可否都开源出来呢,还挺感兴趣的,或者可以把前面的语料分享一下呢,十分感谢。
https://github.com/bojone/simple-chinese-ocr
October 11th, 2016
能提供一下你的数据集吗
数据集由自行收集的字体通过程序生成,程序已经开源,而字体请自行收集。
December 8th, 2016
cn.jpg能说下什么格式么?48*48的灰度图片?
运行报错: "Filter: %r Input: %r" % (filter_size, input_size))
ValueError: Filter must not be larger than the input: Filter: (4, 4) Input: (1, 48)
求指教,谢谢
嗯,48*48的灰度图。
您好,我用pothoshop生成的48*48的灰度图片也是报这个错了。麻烦发一些程序能跑通过的cn.jpg和程序呢。还有main.cp中的 from images import * 是不是写错了,应该是from image import * 。ocr.py中的from images import cut_blank images应该也多了一个s吧。 都是调用的是image.py中的。求完整能调通的代码,万谢。请发到szjw666666@163.com邮箱么。感谢感谢。
April 18th, 2018
[...]OCR技术浅探:6. 光学识别[...]
April 18th, 2019
苏老师,您好。您提到的“在训练模型的时候,我们还对模型最终的损失函数进行了调整,使得高频字的权重更大,这样能够提升模型的预测性能.”那损失函数该如何写呢,如何才能提高频字权重呢?谢谢
keras在fit的时候可以传入sample_weight和class_weight
May 5th, 2019
榛
November 17th, 2022
[...]OCR技术浅探:6. 光学识别[...]
November 17th, 2022
[...]OCR技术浅探:6. 光学识别[...]
April 1st, 2023
[...]OCR技术浅探:6. 光学识别[...]