






4
Dec
开局一段扯,数据全靠编?真被一篇“神论文”气到了
By 苏剑林 | 2021-12-04 | 70559位读者 |这篇文章谈一下笔者被昨天出来的一篇“神论文”气到了的经历。
这篇“神论文”是《How not to Lie with a Benchmark: Rearranging NLP Leaderboards》,论文的大致内容是说目前很多排行榜算平均都用算术平均,而它认为几何平均与调和平均更加合理。最关键是它还对GLUE、SuperGLUE等榜单上的模型用几何平均和调和平均重新算了一下排名,结果发现那些超过人类的模型在新的平均方案下都没超过人类了。
看上去是不是觉得挺有意思的?我也觉得挺有意思的,所以打算写一篇博客介绍一下它。结果博客快写完了,然后在对数据的时候,发现里边表格的数据全是乱来的!!!真实的结果完全不支撑它的结论!!!所以,这篇博客就从“表扬大会”变成了“批评大会”...
胡说八道 #
首先我们来请出“神论文”的第一个表格,它是关于GLUE榜单上的部分成绩:
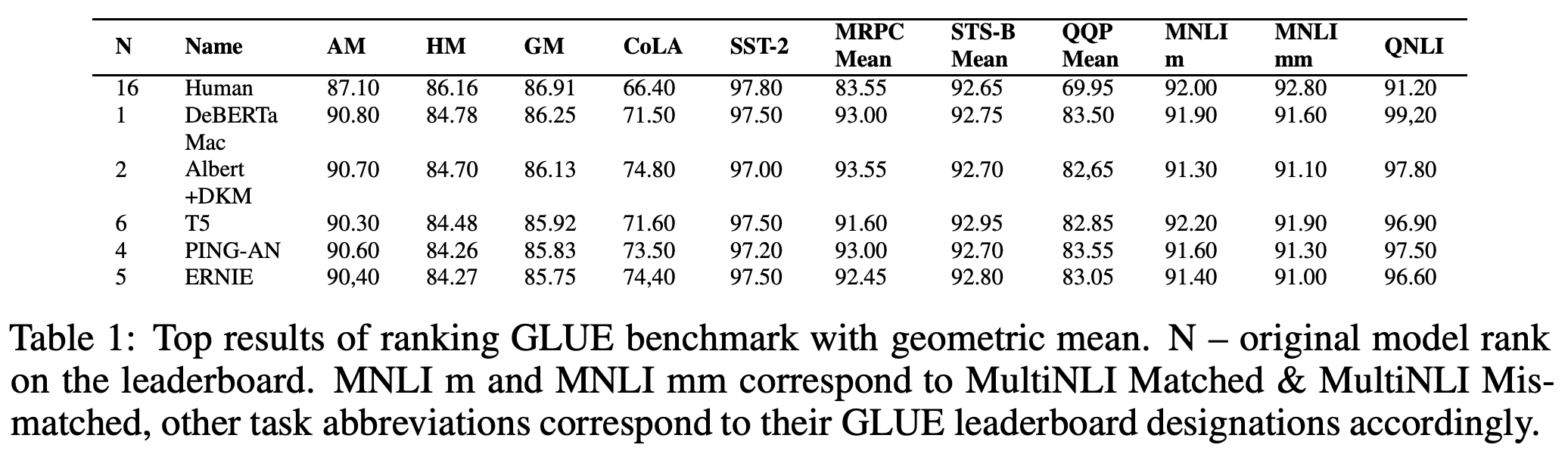
“神论文”的GLUE榜单计算结果
咱别的不说,这篇“神论文”表格里边的“,”(半角逗号)和“.”(小数点)不分,也是够让人恶心的了(下面SuperGLUE的表格更甚)。不过要只是这种小问题,那忍忍也就算了,最不可忍的是:它里边的AM(算术平均)、GM(几何平均)、HM(调和平均)的计算规则简直是“随心所欲”!
我试了很久,终于试出了该表格的计算规则:
1、所有的AM都是用前10个任务的成绩算出来的(虽然上表只显示了前8个任务的成绩);
2、Human那一行的GM、HM用的是前10个任务的成绩来算的;
3、其他行的模型的GM、HM是用全部11个任务的成绩来算的。
由于第11个任务的成绩比其他任务要低,所以这样算出来的模型的GM、HM就比Human的更低,作者就直接得出了在GM、HM之下,人类成绩还是第一名的结论。事实上,如果大家都用同一批任务算,那么AM、GM、HM排名基本无差别。况且,数学思维稍微正常的人都可以看出上述结果的不妥之处:不少任务上模型成绩都远超Human,少数任务上模型不如Human,但也只是低一点点,所以只要是一种正常的平均算法,都不可能得出Human远超模型的结论吧?偏偏作者也就信了...
同样的错误还出现在SuperGLUE上:
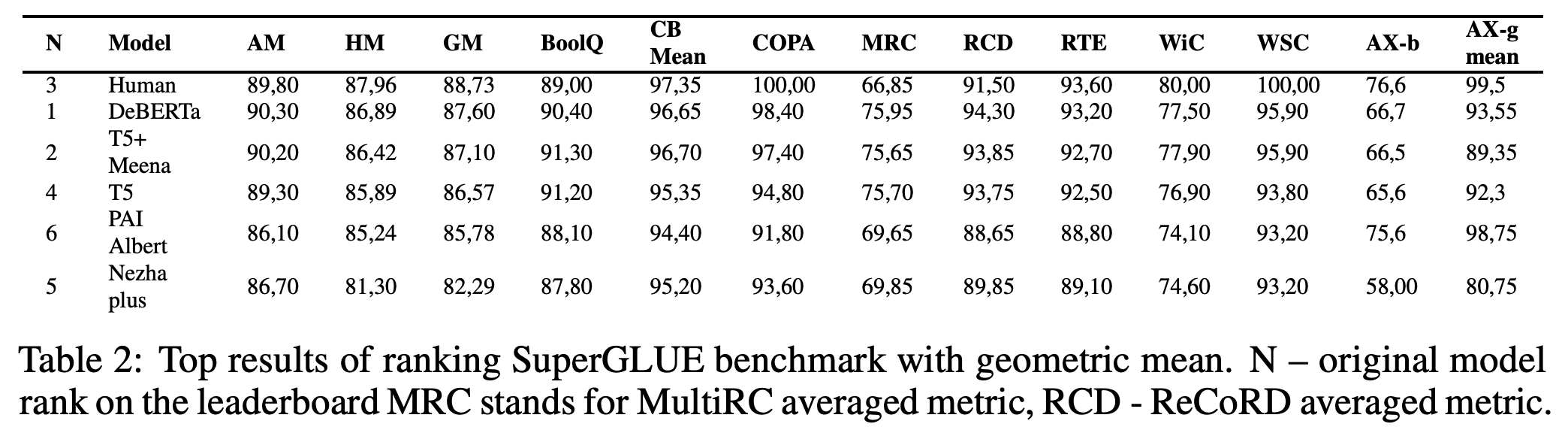
“神论文”的SuperGLUE榜单计算结果
它的计算规则为:
1、所有的AM都是用前8个任务的成绩算出来的;
2、所有GM、HM是用全部10个任务的成绩来算的。
事实上,如果AM也用10个任务的成绩来算,那么按照AM排名人类也是第一名。也就是说,只要大家的计算标准一样,那么AM、GM、HM排名并无太大差别。
真心无奈 #
顺便说,这篇论文还中了NeurIPS 2021的Workshop,虽然Workshop通常都是远不如正式论文,但也不至于乱七八糟到这个程度吧。再看一眼这篇论文的标题,我觉得是不是改为“How not to Lie with this paper”更适合?
看来以后我们看论文的时候,不仅要关心论文成绩的可复现性,还要留意它们的求和、均值、方差等有没有算错~真的是什么奇葩可能性都有~
转载到请包括本文地址:https://www.kexue.fm/archives/8783
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Dec. 04, 2021). 《开局一段扯,数据全靠编?真被一篇“神论文”气到了 》[Blog post]. Retrieved from https://www.kexue.fm/archives/8783
@online{kexuefm-8783,
title={开局一段扯,数据全靠编?真被一篇“神论文”气到了},
author={苏剑林},
year={2021},
month={Dec},
url={\url{https://www.kexue.fm/archives/8783}},
}

December 4th, 2021
沃德天,这样的论文他们都敢发出来,还要不要点脸了 这... 不知道这论文作者是无知还是无畏啊
December 4th, 2021
哈哈哈哈
December 8th, 2021
这已经涉及学术造假了啊,难道不该被撤稿吗?看了一下就两个作者,第二个还是华为诺亚方舟实验室的。。。
我们可以投以最大的善意,称之为“学术失误”。
December 13th, 2021
这个转载是被授权的吗苏神?我看他们没有附上论坛链接,且写的【原创】标签,但是又注明了原作者。https://mp.weixin.qq.com/s/Mwa5J1cw01tOQs4pO23lfQ
这是授权的,里边已经注明了作者名字,并且文末的“阅读原文”就是链接到本博客的。
感谢您的关注哈~
June 30th, 2022
没看到有录用记录,NIPS2021审稿为Reject
https://openreview.net/forum?id=PPGfoNJnLKd
苏神说的是nips21 ICBINB workshop: https://openreview.net/forum?id=AiU1SoiaeMX
December 8th, 2024
苏神当时是不是被气得不行了,博客里不止一处把算数平均(论文里的AM)打成了AH。还是说这是个彩蛋,模仿原论文把小数点打成了逗号的typo。
> 最不可忍的是:它里边的AH(算术平均)
> 1. 所有的AH都是用前10个任务的成绩算出来的
这应该是我的问题,已修正过来。