






11
Nov
当GPT遇上中国象棋:写过文章解过题,要不再来下盘棋?
By 苏剑林 | 2020-11-11 | 80424位读者 |
中国象棋
不知道读者有没有看过量子位年初的文章《最强写作AI竟然学会象棋和作曲,语言模型跨界操作引热议,在线求战》,里边提到有网友用GPT2模型训练了一个下国际象棋的模型。笔者一直在想,这么有趣的事情怎么可以没有中文版呢?对于国际象棋来说,其中文版自然就是中国象棋了,于是我一直有想着把它的结果在中国象棋上面复现一下。拖了大半年,在最近几天终于把这个事情完成了,在此跟大家分享一下。
象棋谱式
将军不离九宫内,士止相随不出官。
象飞四方营四角,马行一步一尖冲。
炮须隔子打一子,车行直路任西东。
唯卒只能行一步,过河横进退无踪。
背棋谱 #
其实,简单看看量子位的文章,就能理解GPT2下象棋的原理了,无非就是“背棋谱”。简单来说,就是象棋的棋谱可以表示为一个连续的文本字符串,而GPT2正是擅长于背诵文本,因此可以用GPT2把人类的棋谱都背诵下来,而对于下棋来说,就可以看成是根据已经走的部分棋谱背诵下一步棋谱了,因此整个任务理论上确实是可以用GPT2完成。
为了完成这个任务,我们就需要了解计算机是如何记谱的。关于记谱的标准,比较通用的是ICCS记谱法和FEN局面表示法,其细节可以参考文章《中国象棋电脑应用规范(二):着法表示》和《中国象棋电脑应用规范(二):FEN文件格式》。
ICCS记谱 #
简单来说,ICCS记谱就是将棋盘用如下图的横纵坐标表示,每一步走法只需要记录起始坐标,比如“h2e2”就是指将原来位于坐标(h, 2)的子移动到(e, 2),如果是当前局面是新开局,那么这就对应着走法“炮二平五”。这样一来每一步就只需要4个字符来记录了,$n$步的棋谱就变成了$4n$长度的字符串了。当然,如果要输入到模型的话,不一定非得要按照这样的方式来,比如我也可以把“h2”只用一个id表示、“e2”用另一个id表示,也就是每个格点都用一个坐标而不是两个坐标来描述,这样每一步的只需要两个id来记录,以此来缩小棋谱的序列长度,这没有什么定法,有兴趣大家自己改进着完就好。
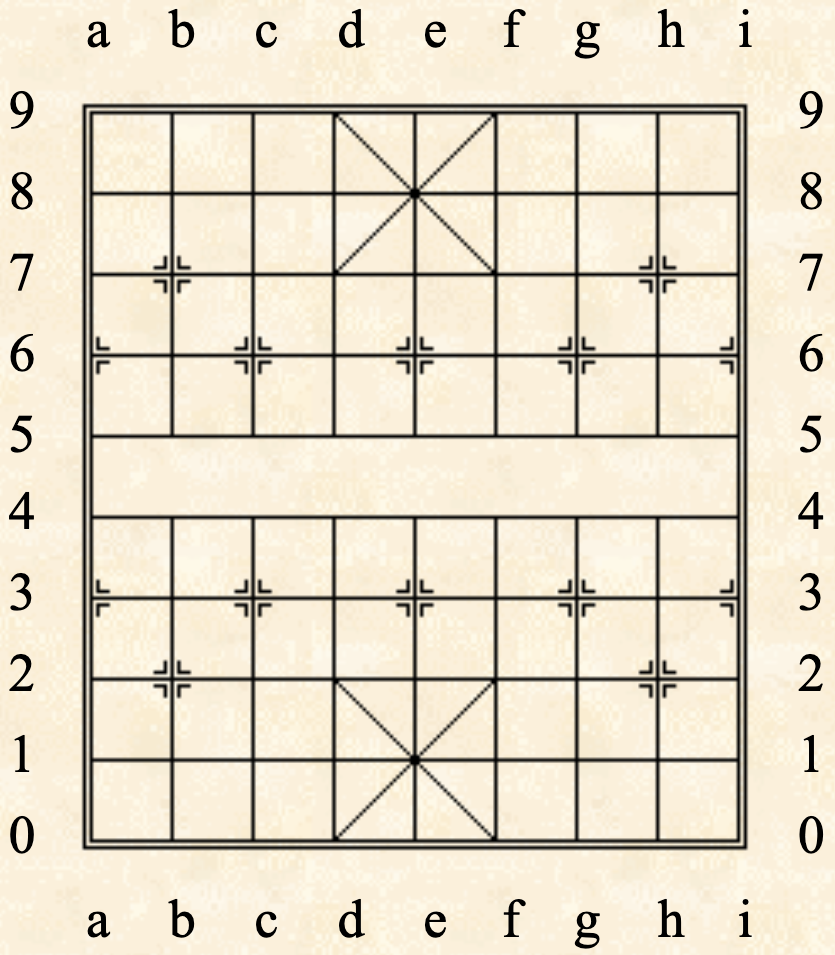
中国象棋棋盘ICCS坐标示意图
FEN局面 #
至于FEN局面表示法,则是用来表示当前局面有哪些子,轮到谁走。本文所建模的棋谱实际上都是全局棋谱,所以实际上本文的模型不需要用到它(局面都是默认的新开局面),不过为了方便有兴趣的读者做出改进,这里也简单介绍下。所谓FEN表示法,主要就是想办法表示出每一行有哪些子,比如开局表示为“rnbakabnr/9/1c5c1/p1p1p1p1p/9/9/P1P1P1P1P/1C5C1/9/RNBAKABNR w - - 0 1”。其中红色部分表示局面,小写表示黑方,大写表示红方,不同行之间用/隔开,字母含义如下表。这样,“rnbakabnr”就表示第一行为黑子的“車馬象士將士象馬車”,“9”表示第二行9个点都是空白的,“1c5c1”表示第三行是“1个空白+1个黑砲+5个空白+1个黑砲+1个空白”,等等;绿色部分表示轮到哪一方走子,“w”表示红方,“b”表示黑方;剩下部分一般不大重要,有兴趣的读者自己去看链接就行。
\begin{array}{c}
\text{中国象棋fen表示法含义表} \\
{\begin{array}{c|c|c|c|c|c|c}
\hline
\color{red}{R}/\color{black}{r} & \color{red}{N}/\color{black}{n} & \color{red}{B}/\color{black}{b} & \color{red}{A}/\color{black}{a} & \color{red}{K}/\color{black}{k} & \color{red}{C}/\color{black}{c} & \color{red}{P}/\color{black}{p} & \text{阿拉伯数字}m\\
\hline
\color{red}{\text{俥}}/\color{black}{\text{車}} & \color{red}{\text{傌}}/\color{black}{\text{馬}} & \color{red}{\text{相}}/\color{black}{\text{象}} & \color{red}{\text{仕}}/\color{black}{\text{士}} & \color{red}{\text{帥}}/\color{black}{\text{將}} & \color{red}{\text{炮}}/\color{black}{\text{砲}} & \color{red}{\text{兵}}/\color{black}{\text{卒}} & \text{表示连续}m\text{个空位} \\
\hline
\end{array}}
\end{array}
建模型 #
看了上述对记谱表示的介绍,我们知道,不管是每步的走法还是局面的表示,都被我们转化为了一串文本了,而对于象棋的推演都是以局面与走法作为输入输出的,所以理论上来说象棋的建模完全就是一个“文本处理”问题!这便是GPT2下象棋的理论依据了。本质上来讲,GPT也就是BERT加上语言模型的Attention Mask,所以这样的做法我们说是BERT下象棋或者GPT下象棋都行~
代码分享 #
模型原理就没什么好写的了,之前就有文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》介绍,相关的例子有《基于Conditional Layer Normalization的条件文本生成》、《BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题》等,读者可以自行翻看。本文的处理其实很简单,就是只保留全局棋谱,将棋谱的ICCS记法当成一个长句子,然后训练一个语言模型。
项目链接:https://github.com/bojone/gpt_cchess
训练过程使用渐进式训练,即逐步增加序列长度,而不是一次性使用同一的长度,有些文章将这种做法称之为“课程学习(Curriculum Learning)”。这种做法能提高模型的训练速度和收敛速度(一开始序列更短,训练速度更快,也更容易收敛),直观来看就是让模型先学习“开局”,然后再学习“开局+中局”,最后学习“开局+中局+残局”,逐步增加难度。训练前加载了BERT的权重,可能读者会疑问BERT的权重还能跟棋谱有关系?其实没什么关系,但是不管怎么说,用BERT的权重比完全随机初始化的权重要好点,收敛会快一点点。
测试一下 #
模型脚本还包含了一个可以跟模型交互式下棋的实现,读者可以自行体验一下,这个交互式下棋使用了python的cchess模块来辅助实现,在此表示感谢。GPT本身是一个生成模型,但是在决定下一步棋走什么的时候,笔者并不是用生成式方法(因为无约束生成有可能输出不可行的走法),而是用打分式的方法,即直接生成当前局面的所有可行走法,然后输入到模型打分,取分数最高的那个走法,这样就保证模型输出的每一步都是可行的,保证了可以跟AI一直对局下去,直到分出输赢。
交互式下棋效果
也许读者可能会有疑问,枚举所有可行走法计算量会不会很大?其实,对于每个局面来说,可行走法并不多,可以通过简单论证它不会超过111种(是不是有点意外?中国象棋每一步的候选走法不超过111种,而不是一个非常大的数字),所以这一步的batch_size不会超过111,因此是可以接受的。
推导过程很简单:1个车或炮最多有17种走法,2车2炮最多有68种走法;兵如果都过河了,那么每个兵最多有3种走法,5个兵最多有15种走法;1个马最多有8种走法,2个马就是16种;2个相最多有6种走法(1个在中间,1个在边,4+2);1个士在花心最多有4种走法(2个士反而相互堵塞);最后的帅最多有2种走法。因此结果是68+15+16+6+4+2=111。具体局面设计可以参考数学研发论坛的《一个中国象棋局面设计难题》。
大家最关心的可能就是这样弄出来的模型棋力究竟怎样?笔者简单跟它测了一下,大概的结论是:基本上可以开一个比较好的局,开局的时候具有不错的应变能力,不过一旦到了中局之后,应变能力会大大下降。对于吃子不是很敏感,也就是说当你乱吃它的子的时候,它可能不会应对。可以看出这些其实都是纯背棋谱的缺点。当然,前面说了每一步的输出都是可行,因此你可以跟它一直玩下去,直到把棋下完。
谈改进 #
应该有读者会问能不能自己跟自己对弈来提高棋力?理论上当然是可以的,但很遗憾这里没有实现,一是没那个心思实现,二是没那个算力实现。此外,增加模型大小应该也能进一步提升棋力,要注意笔者上述结果只用了Base版本(1亿参数)的模型,本文开头提到的网友用GPT2下国际象棋可是用了15亿参数的GPT2,是我们的15倍。还有一个改进的地方,那就是上面的建模中我们直接学习了整个对局棋谱,按道理为了更好的棋力我们可以只学习赢家的走法,不能学习输家的走法。
当然,这些做法就算有提升,估计也是有限的,归根结底,这跟我们所理解的下棋原理不一样。我们下棋是根据局面形势往前推的,但上述的语言模型做法则没有局面这个概念,或者说它的局面需要用已经走的所有步骤来确定,这对于中后局来说历史步数太多,确实有点强模型所难了。改进方法其实也很简单,改为“以局面为输入、以走法为输出”就好了,前面我们说了,局面也可以用FEN表示法表示为一个文本,因此这也是只是个Seq2Seq任务而已。
除此之外,还有一些别的做法,比如我们可以把赢家的每一个局面都当作正样本,输家的每一个局面都当作负样本,那么就可以训练一个二分类模型,来判断局面优劣,有了这个判断函数,我们也可以直接枚举每一个可行走法,根据判断函数的结果来选择最优下法。而局面可以表示为文本,这就意味这我们将下棋变成了一个文本分类任务了。
总之,得益于Transformer模型对文本的强大的建模能力,这使得我们对下棋的建模思路也变得简单多样起来了~
总小结 #
本文尝试了通过bert4keras用GPT来下中国象棋的做法,主要思路是通过“语言模型背棋谱”的方式来让模型具有预测下一步的能力,并谈及了一些改进思路。尽管本文的做法并非对下棋这个任务进行建模的标准做法,但通过这样的方式,能让我们进一步体会到语言模型的强大之处。
欢迎大家报告自己所训练的下棋模型的棋力智商,哈哈~

送你一对象
转载到请包括本文地址:https://www.kexue.fm/archives/7877
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 11, 2020). 《当GPT遇上中国象棋:写过文章解过题,要不再来下盘棋? 》[Blog post]. Retrieved from https://www.kexue.fm/archives/7877
@online{kexuefm-7877,
title={当GPT遇上中国象棋:写过文章解过题,要不再来下盘棋?},
author={苏剑林},
year={2020},
month={Nov},
url={\url{https://www.kexue.fm/archives/7877}},
}

November 12th, 2020
苏神 可否分享一个 训练好的权重,这个batchsize的roberta训练太吃力
我就知道有人会提这个需求...已经分享了,请刷新到github首页找~
November 12th, 2020
苏神,用bert4keras的pretraining代码微调模型,职能保存ckpt文件,请问怎么保存bert_model.ckpt.meta文件呢?
就是把训练好的roberta模型保存成标准的tf格式,以便其他人调用,或者有什么方法能转换成tf的标准模型呢,求解
有save_weights_as_checkpoint方法可以转,最新版的save_weights_as_checkpoint支持保存meta了(旧版的没有meta)。
苏神说的是Transformer类下的save_weights_as_checkpoint方法吗?但是在pretraining这个函数中,训练的模型train_model没有这个方法
苏神我直接在:
with strategy.scope():
train_model = build_transformer_model_for_pretraining()
train_model.summary()
这段代码前返回了bert:
with strategy.scope():
bert, train_model = build_transformer_model_for_pretraining()
train_model.summary()
然后在回调函数里面用bert.save_weights_as_checkpoint(model_save_path)
这样确实可以保存tf标准模型了,你看这样可以么?
是的,就是这样。
好的,谢谢苏神
那,苏神,save_weights_as_checkpoint的转换方法可以告诉下吗?就是之前没用这种方法保存的模型,现在想转换成tf标准模型,要怎么做呢?
@MECH SIHAO|comment-14780
很简单啊,你只需要用load_weights把原来的模型加载进去,然后再用save_weights_as_checkpoint保存不就行了~
我刚开始也是这样想的,我是用pretraining代码,把train_model.fit给删除了,然后直接bert.save_weights_as_checkpoint(model_save_path),
但是原来用save_model_weights保存的模型,在导入时会报错:
Key bert/embeddings/word_embeddings not found in checkpoint
@MECH SIHAO|comment-14783
我说的是你用原来的方法建立好模型,然后用model.load_weights加载你之前保存好的权重,再用save_weights_as_checkpoint转换。
好的,谢谢苏神
November 18th, 2020
主要还是有错进错出的对局,不能把赢家的每一个局面都当作正样本,反之亦然
相对而言吧,高手也有漏招的时候呀,但是高手的漏招一般都比普通人要高级了。(捂脸)
April 7th, 2021
苏老师,可以考虑试着出一个Curriculum Learning的博客吗?最近看ACL2020有关bert+Curriculum Learning感觉很吃力(论文:Curriculum Learning for Natural Language Understanding)
对这个课题不关心,以后有机会再说吧。
June 7th, 2021
说到底还是要使用增强学习呀