






7
Feb
你的CRF层的学习率可能不够大
By 苏剑林 | 2020-02-07 | 146645位读者 |CRF是做序列标注的经典方法,它理论优雅,实际也很有效,如果还不了解CRF的读者欢迎阅读旧作《简明条件随机场CRF介绍(附带纯Keras实现)》。在BERT模型出来之后,也有不少工作探索了BERT+CRF用于序列标注任务的做法。然而,很多实验结果显示(比如论文《BERT Meets Chinese Word Segmentation》)不管是中文分词还是实体识别任务,相比于简单的BERT+Softmax,BERT+CRF似乎并没有带来什么提升,这跟传统的BiLSTM+CRF或CNN+CRF的模型表现并不一样。
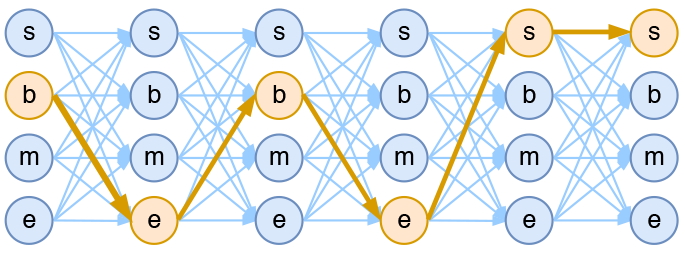
基于CRF的4标签分词模型示意图
这两天给bert4keras增加了用CRF做中文分词的例子(task_sequence_labeling_cws_crf.py),在调试过程中发现了CRF层可能存在学习不充分的问题,进一步做了几个对比实验,结果显示这可能是CRF在BERT中没什么提升的主要原因,遂在此记录一下分析过程,与大家分享。
糟糕的转移矩阵 #
由于笔者用的是自己实现的CRF层,所以为了证明自己的实现没有错误,笔者跑完BERT+CRF的实验(BERT用的是base版本)后,首先观察了转移矩阵,大体数值如下:
$$\begin{array}{c|cccc}
& s & b & m & e \\
\hline
s & -0.0517 & -0.459 & -0.244 & 0.707 \\
b & -0.564 & -0.142 & 0.314 & 0.613 \\
m & 0.196 & -0.334 & -0.794 & 0.672 \\
e & 0.769 & 0.841 & -0.683 & 0.572 \\
\end{array}$$
其中第$i$行$j$列的数值表示从$i$转移到$j$的得分(记为$S_{i\to j}$),其中分值的绝对值并没有意义,只有相对比较的意义。顺便说明下,本文的中文分词用的是$(s,b,m,e)$的字标注法,如果不了解可以参考《【中文分词系列】 3. 字标注法与HMM模型》。
然而,直观来看,这并没有学到一个好的转移矩阵,甚至可能会带来负面影响。比如我们看第一行,$S_{s\to b} = -0.459$,$S_{s\to e}=0.707$,即$S_{s\to b}$明显小于$S_{s\to e}$。但是,根据$(s,b,m,e)$的标注设计,$s$后面是有可能接$b$的,但不可能接$e$,所以$S_{s\to b} < S_{s\to e}$是明显不合理的,它可能引导出不合理的标注序列,理想情况下$S_{s\to e}$应该为$-\infty$才对。
这样不合理的转移矩阵一度让笔者觉得是自己的CRF实现得有问题,但经过反复排查以及对比Keras官方的实现,最终还是确认自己的实现并没有错误。那么问题出现在哪呢?
学习率的不对等 #
如果我们先不管这个转移矩阵的合理性,直接按照模型的训练结果套上Viterbi算法去解码预测,然后用官方的脚本去评测,发现F1有96.1%左右(PKU任务上),已经是当前最优水平了。
转移矩阵很糟糕,最终的结果却依然很好,这只能说明转移矩阵对最终的结果几乎没有影响。什么情况下转移矩阵几乎没影响呢?可能的原因是模型输出的每个字的标签分数远远大于转移矩阵的数值,并且区分度已经很明显了,所以转移矩阵就影响不到整体的结果了,换言之这时候直接Softmax然后取argmax就很好了。为了确认,我随机挑了一些句子,观察模型输出的每个字的标签分布,确实发现每个字的分数最高的标签分数基本都在6~8之间,而其余的标签分数基本比最高的要低上3分以上,这相比转移矩阵中的数值大了一个数量级以上,显然就很难被转移矩阵影响到了。这就肯定了这个猜测。
一个好的转移矩阵显然会对预测是有帮助的,至少能帮助我们排除不合理的标签转移,或者说至少能保证不会带来负面影响。所以值得思考的是:究竟是什么阻止了模型去学一个好的转移矩阵呢?笔者猜测答案可能是学习率。
BERT经过预训练后,针对下游任务进行finetune时,只需要非常小的学习率(通常是$10^{-5}$量级),太大反而可能不收敛。尽管学习率很小,但对于多数下游任务来说收敛是很快的,很多任务都只需要2~3个epoch就能收敛到最优。另一方面,BERT的拟合能力是很强的,所以它能比较充分地拟合训练数据。
这说明什么呢?首先,我们知道,每个字的标签分布是直接由BERT模型算出来的,而转移矩阵是附加的,与BERT没直接关系。当我们以$10^{-5}$量级的学习率进行finetune时,BERT部分迅速收敛,也就是每个字的标签分布会迅速被拟合,同时因为BERT的拟合能力比较强,所以迅速拟合到一个比较优的状态(即目标标签打分很高,并且拉开了与非目标标签的差距)。而由于转移矩阵跟BERT没什么联系,当逐字标签分布迅速地收敛到较优值时,它还是以$10^{-5}$的速度“悠哉悠哉”地前进着,最终要比逐字标签的分数低一个数量级。而且,当逐字标签分布都已经能很好拟合目标序列了,也就不再需要转移矩阵了(转移矩阵的梯度会非常小,从而几乎不更新)。
思考到这里,一个很自然的想法是:能不能增加CRF层的学习率?笔者尝试增大CRF层的学习率,经过多次实验,发现CRF层的学习率为主体学习率的100倍以上时,转移矩阵开始变得合理起来了,下面是BERT主体学习率为$10^{-5}$、CRF层的学习率为$10^{-2}$(即1000倍)时,训练出的一个转移矩阵
$$\begin{array}{c|cccc}
& s & b & m & e \\
\hline
s & 3.17 & 2.16 & -3.97 & -2.04 \\
b & -3.89 & -0.451 & 1.67 & 0.874 \\
m & -3.9 & -4.41 & 3.82 & 2.45 \\
e & 1.88 & 0.991 & -2.48 & -0.247 \\
\end{array}$$
这样的转移矩阵是合理的,量级也是对的,它学习到了正确的标签转移,比如$s\to s,b$比$s\to m,e$分数大、$b\to m,e$比$b\to s,b$分数大,等等。不过,就算调大了CRF层的学习率,结果相比不调整时没有明显优势,归根结底,BERT的拟合能力太强了,就连Softmax效果都能达到最优了,转移矩阵自然也不能带来太大的提升。
(附注:增大学习率的实现技巧可以参考《“让Keras更酷一些!”:分层的学习率和自由的梯度》。)
更多的实验分析 #
CRF没给BERT带来什么效果变化,原因是BERT的拟合能力太强了,导致不需要转移矩阵效果都很好。那如果降低BERT的拟合能力,会不会带来显著差异呢?
前面的实验中是使用BERT base的第12层的输出来finetune的,现在我们只用第1层的输出来进行finetune,来测试上述调整是否会带来显著性差异。结果如下表:
$$\begin{array}{c|cc|cc}
\hline
& \text{主体学习率} & \text{CRF学习率} & \text{Epoch 1的测试集F1值} & \text{最优的测试集F1值}\\
\hline
\text{CRF-1} & 10^{-3} & 10^{-3} & 0.914 & 0.925\\
\text{CRF-2} & 10^{-3} & 10^{-2} & \textbf{0.929} & \textbf{0.930}\\
\text{CRF-3} & 10^{-2} & 10^{-2} & 0.673 & 0.747\\
\text{Softmax} & 10^{-3} & \text{-} & 0.899 & 0.907\\
\hline
\end{array}$$
由于只用了1层BERT,所以主体学习率设置为$10^{-3}$(模型越浅,学习率可以适当地越大),主要对比的是调整CRF层学习率所带来的提升。从表格可以看到:
1、适当的学习率下,CRF比Softmax有提升;
2、适当增加CRF层的学习率也会比原来的CRF有一定提升。
这说明,对于拟合能力不是特别强大的模型(比如只用BERT的前几层,或者对于某些特别难的任务来说,完整的BERT拟合能力也不算充分),CRF及其转移矩阵还是有一定帮助的,而精调CRF层的学习率能带来更大的提升。此外,上述所有的实验都是基于BERT进行的,对于传统的BiLSTM+CRF或CNN+CRF来说同样的做法有没有效果呢?笔者也简单实验了一下,发现有些情况下也是有帮助的,所以估计这是CRF层的一个通用技巧。
内容简单汇总 #
本文从给bert4keras添加的CRF例子出发,发现BERT与CRF结合的时候,CRF层可能存在训练不充分的问题,进而猜测了可能的原因,并通过实验进一步肯定了猜测,最后提出通过增大CRF层学习率的方式来提升CRF的效果,初步验证了(在某些任务下)其有效性。
转载到请包括本文地址:https://www.kexue.fm/archives/7196
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Feb. 07, 2020). 《你的CRF层的学习率可能不够大 》[Blog post]. Retrieved from https://www.kexue.fm/archives/7196
@online{kexuefm-7196,
title={你的CRF层的学习率可能不够大},
author={苏剑林},
year={2020},
month={Feb},
url={\url{https://www.kexue.fm/archives/7196}},
}

December 20th, 2022
[...]你的CRF层的学习率可能不够大[...]
December 21st, 2022
[...]来源:苏剑林. (Feb. 07, 2020). 《你的CRF层的学习率可能不够大 》[Blog post]. Retrieved from https://kexue.fm/archives/7196[...]
June 4th, 2023
[...]你的CRF层的学习率可能不够大[...]
June 25th, 2023
苏佬您好,我想请教一下使用from bert4keras.models import BERT这个,有没有对应bert里面的 attention_mask,就是填充位是0,手动或者自动实现进bert里面填充位不进行运算,输出时填充位对应的值是0.
试了好多写法,查了好多资料没有解决这个难题: