






2
Jul
用Pandas实现高效的Apriori算法
By 苏剑林 | 2015-07-02 | 180746位读者 |最近在做数据挖掘相关的工作,阅读到了Apriori算法。平时由于没有涉及到相关领域,因此对Apriori算法并不了解,而如今工作上遇到了,就不得不认真学习一下了。Apriori算法是一个寻找关联规则的算法,也就是从一大批数据中找到可能的逻辑,比如“条件A+条件B”很有可能推出“条件C”(A+B-->C),这就是一个关联规则。具体来讲,比如客户买了A商品后,往往会买B商品(反之,买了B商品不一定会买A商品),或者更复杂的,买了A、B两种商品的客户,很有可能会再买C商品(反之也不一定)。有了这些信息,我们就可以把一些商品组合销售,以获得更高的收益。而寻求关联规则的算法,就是关联分析算法。
啤酒与尿布 #

啤酒与尿布
关联算法的案例中,最为人老生常谈的应该是“啤酒与尿布”了。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,超市管理人员发现“啤酒与尿布两件看上去毫无关系的商品会经常出现在同一个购物篮中”。经过分析,原来在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。因此,沃尔玛尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品。事实是效果相当不错!
(注:这个故事的真实性是被人怀疑的,但无论如何,它已经成为了介绍关联分析的著名、显浅的案例。)
Apriori算法 #
如何从一大批购买记录中,找到像“啤酒与尿布”之类的关联规则?很有多关联分析算法,其中最简单的应该是Apriori算法了(当然效率也不高,但是作为入门算法,还是相当不错的。)关于Apriori算法的详细内容,本文不作介绍,因为网上已经有太多类似的内容了,而且现有内容都已经不错了。推荐阅读:
https://zh.wikipedia.org/zh-cn/关联式规则
http://hackerxu.com/2014/10/18/apriori.html
Python实现 #
经过几天的调试,终于用Python实现了一个比较高效的Apriori脚本。当然,这里的高效是就Apriori算法本身而言的,不涉及到对算法本身的改进。算法利用了Pandas库,在保证运行效率的前提下,基本实现了代码最短化。读者可以发现,这里比网上找到的很多Apriori算法的代码(不限于Python代码)都要短,效率都要高。
代码同时兼容Python 2.x和3.x,当然前提是安装好Pandas。本代码基本可以处理几万条记录,数十个候选项的关联分析问题,当然,前提是需要耐心等待。
算法的效率问题 #
Apriori算法的运行时间取决于很多因素,比如数据量、最小支持度(但是跟最小置信度没什么关系)、候选项个数等,以购物篮分析为例,首先,运行的时间当然直接取决于购物记录的条数$N$,但是跟$N$的关系仅仅是线性的。其次,最小支持度是几乎具有决定性的,它对运行时间很有影响,但是其影响又得具体问题具体分析,此外它很大程度上也决定了最终产生的规则数目。最后是候选项的数目$k$,也就是所有购物车记录中,总共出现了多少种商品,这个也是决定性的,如果$k$本身比较大,后面依次连接,那么项数将是$k^2$、$k^3$...(近似),对速度的的影响是致命的。
因此,Apriori算法思路是简单了,但是效率却不高。
代码 #
#-*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd
d = pd.read_csv('apriori.txt', header=None, dtype = object)
print(u'\n转换原始数据至0-1矩阵...')
import time
start = time.clock()
ct = lambda x : pd.Series(1, index = x)
b = map(ct, d.as_matrix())
d = pd.DataFrame(list(b)).fillna(0)
d = (d==1)
end = time.clock()
print(u'\n转换完毕,用时:%0.2f秒' %(end-start))
print(u'\n开始搜索关联规则...')
del b
support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
ms = '--' #连接符,用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence):
import time
start = time.clock()
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果
support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort(['confidence','support'], ascending = False) #结果整理,输出
end = time.clock()
print(u'\n搜索完成,用时:%0.2f秒' %(end-start))
print(u'\n结果为:')
print(result)
return result
find_rule(d, support, confidence).to_excel('rules.xls')测试数据集:apriori.txt
运行结果:
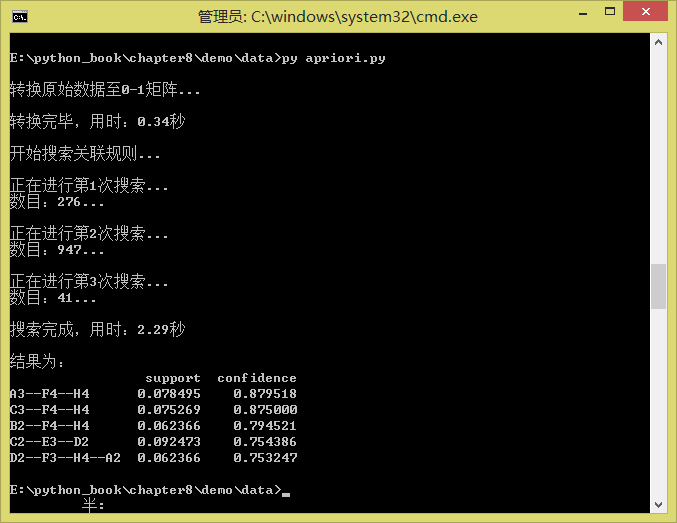
apriori
转载到请包括本文地址:https://www.kexue.fm/archives/3380
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jul. 02, 2015). 《用Pandas实现高效的Apriori算法 》[Blog post]. Retrieved from https://www.kexue.fm/archives/3380
@online{kexuefm-3380,
title={用Pandas实现高效的Apriori算法},
author={苏剑林},
year={2015},
month={Jul},
url={\url{https://www.kexue.fm/archives/3380}},
}

December 15th, 2016
'(但是跟最小置信度没什么关系)、候选项个数等,以购物篮分析为例,首先,运行的时间当然直接取决于购物记录的条数N,但是跟N的关系仅仅是线性的。其次,最小置信度是几乎具有决定性的,它对运行时间很有影响,',这段话笔误了。博主很多文章写得都不错,谢谢分享。
感谢提出,已经修改。
February 17th, 2017
[...]如《中医证型关联规则挖掘》中Apriori关联规则代码抄袭自苏剑林《用Pandas实现高效的Apriori算法》一文,书中代码(写此文章时还未改正)[...]
抱歉,之前没有注意博主是作者之一,再次抱歉
March 14th, 2017
感谢您的分享,您代码中的第5行 d = pd.read_csv('apriori.txt', header=None, dtype = object)
请问这个原始数据集 ‘apriori.txt’,长什么样子呢?
下面楼主有附件啊亲
October 2nd, 2017
输出格式是不是有问题? 都用--连接,怎么表示规则,如A3--F4--H4,怎么理解是哪个退出哪个?
前面n-1个联合推出第n个。你可以理解为P(H4|A3,F4)很大。
November 20th, 2017
result = result.T.sort(['confidence','support'], ascending = False)在python3.6.2中报错,怎么弄?
sort改成sort_values试试
好了,谢谢您
为什么我的还是报错呢
January 22nd, 2018
请问如何读取数量不相等的事务数据,不像案例那样,每条都是7种数据,数量不相等用pandas读取会报错
有同样问题 但是也可以处理为0 不过 我这的订单具有不确定性 不知楼主有什么好的解决方案 另外我load楼主的代码 2.7执行 报了
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 69: ordinal not in range(128) 求解
我试了把列数补齐 并默认为0 报的是这个 pandas.core.indexes.base.InvalidIndexError: Reindexing only valid with uniquely valued Index objects
我过段时间抽空把代码升级一下哈。
我也遇到相同的问题,请问有解决的办法吗?
https://kexue.fm/archives/5525
March 18th, 2018
請問我的事务数据改成下列這樣,出來變得很奇怪 可以請問為什麼嗎?
I1 I2 I5
I2 I4
I2 I3
I1 I2 I4
I1 I3
I2 I3
I1 I3
I1 I2 I3 I5
I1 I2 I3
目前暂时不支持这种格式的输入~
新版本已经支持变长输入
https://kexue.fm/archives/5525
April 24th, 2018
result = result.T.sort(['confidence','support'], ascending = False)
报以下错误:
AttributeError: 'DataFrame' object has no attribute 'sort'
解决方式:
sort_values()即可解决
July 3rd, 2019
InvalidIndexError: Reindexing only valid with uniquely valued Index objects
这个错误怎么解决,在转换0-1矩阵时发现的错误
September 18th, 2019
你好,将数据集替换为中文字符后报错,请问是哪里出了问题?谢谢
不知道,没试过中文的,也没空调试了,你看着改吧。