






22
May
MoE环游记:8、强制序列级均衡
By 苏剑林 | 2026-05-22 | 1465位读者 |到目前为止,“MoE环游记”系列已经写了7篇文章,其中5篇都是围绕着MoE的路由和负载均衡展开的。从路由的形式来看,它们可以分为静态计算和动态计算两类;从实现负载均衡的方法上看,它们又可以分为Aux-Loss和Loss-Free两类,其中Loss-Free又可以DeepSeek所提的SignSGD方案以及笔者所提的QB方案。
还有一个细节是,我们此前讨论的Loss-Free方案,都是在实现全局批次意义下的均衡,而很多时候我们会加上一个序列级的Aux Loss,来避免序列级的极端不均衡。如果我们相信每个Aux-Loss方案都有对应的Loss-Free版本,那么序列级的Loss-Free均衡,又应该怎么实现呢?这便是文本要探讨的主题。
前文回顾 #
首先让我们回顾一下之前关于负载均衡的探讨。在文章《MoE环游记:2、不患寡而患不均》中,我们首次讨论MoE的负载均衡问题,所提的解决方案为Aux Loss,即添加额外的损失函数来促进均衡,Aux Loss的问题是有额外的权重系数要调,优点是可以随意调节均衡的颗粒度,可以实现序列、分组或者全局层次的均衡(当然越全局通信也越大)。
从《MoE环游记:3、换个思路来分配》开始,我们讨论Loss-Free形式的负载均衡策略,它通过引入一个额外的偏置项来调节均衡程度,并手工设计SignSGD形式的规则来更新偏置项,这种模式比Aux Loss更灵活且对Infra友好。在《MoE环游记:4、难处应当多投入》中,我们将它推广到了动态激活数量的MoE。
而在《MoE环游记:6、最优分配促均衡》中,我们从最优分配的视角看待负载均衡问题,通过交替求解对偶目标,我们得到了一种新的负载均衡策略Quantile Balancing(QB)。单从结果上来看,它可以视为Loss-Free方案偏置项的一种新的更准确的求解方案。接着,在《MoE环游记:7、动态激活极简解》中我们同样将QB推广到了动态MoE。
这里有一个细节,Loss-Free引入的偏置项是全局共享的,所以目前所有的Loss-Free方案,无一例外只能实现全局负载均衡。刚才说了,如果我们需要的话,Aux Loss也可以用于促进序列级均衡,那么Loss-Free是否也有对应的序列级均衡的方案呢?
局部中心 #
无独有偶,@ChangJonathanC 在文章《Causal Routing Bias for Aux-Loss-Free MoE Training》中也进行过相关探索,作者提出了两种思路,我们先来简单学习一下,也便于跟我们后面自己的思路进行对比。设$\boldsymbol{s}\in\mathbb{R}^{l\times n}$表示一个长度为$l$的序列的Router输出,$\boldsymbol{s}_i\in\mathbb{R}^n$则表示第$i$个token的Router输出。文章所提的第一个思路是,将$\boldsymbol{s}$减去它的滑动平均(EMA):
\begin{equation}\hat{\boldsymbol{s}}_i = \boldsymbol{s}_i - \bar{\boldsymbol{s}}_i,\qquad \bar{\boldsymbol{s}}_i = \gamma\bar{\boldsymbol{s}}_{i-1} + (1 - \gamma)\boldsymbol{s}_i\end{equation}
然后用$\hat{\boldsymbol{s}}$去决定去激活哪些Expert(比如选Top-$k$,也可以结合QB等手段使用)。这个做法背后的思想很朴素:直观来想,如果用$\boldsymbol{s}$来做决策时Expert $j$被激活的次数多,那么意味着它的打分$\boldsymbol{s}_{:,j}$平均来说偏大,因此为了均衡,应该对它做相应的惩罚,惩罚的量正是由EMA估算的局部平均值。
这样一来,在新的$\hat{\boldsymbol{s}}$中,每个Expert的分数在局部都近似具有零均值,不至于让某个Expert更为“突出”,从而实现序列级均衡。然而,这只是一个经验做法,并没有理论确保它一定会更均衡,笔者简单做过测试,像第一层MoE之类的极端不平衡场景,它并没有带来实质帮助。也许作者也意识到了这个局限性,所以他提出了第二种方案。
测试训练 #
第二种方案的思路其实也挺直观。在《MoE环游记:3、换个思路来分配》中,我们不是引入了一个偏置项来控制全局的均衡性吗?这个偏置项用SignSGD来更新。既然如此,我们可以模仿TTT的“测试时训练”思想,沿着序列维度逐Token地激活Expert,并根据已经激活的分布情况,更新这个偏置项。
以$\boldsymbol{s}\in\mathbb{R}^{l\times n}$和Top-$k$版MoE为例,原本的Loss-Free方案,是引入全局的偏置向量$\boldsymbol{\beta}\in\mathbb{R}^n$,然后将激活机制改为逐$\boldsymbol{s}_i - \boldsymbol{\beta}$选Top-$k$。而这里的想法是为每个$\boldsymbol{s}_i$都分配一个$\boldsymbol{\beta}_i\in\mathbb{R}^n$,激活机制改为$\boldsymbol{s}_i - \boldsymbol{\beta}_i$选Top-$k$。$\boldsymbol{\beta}_i$的更新规则可以是符号梯度上升
\begin{equation}\boldsymbol{\beta}_i = \boldsymbol{\beta}_{i-1} + \eta\mathop{\text{sign}}(\boldsymbol{f}_{\leq i-1} - 1/n)\end{equation}
这里$\boldsymbol{f}_{\leq i-1}$是截止到第$i-1$个Token的已激活的Expert分布。作者最后的版本做了一些调整:把符号函数去掉,并将$\boldsymbol{f}_{\leq i-1}$改成了$\boldsymbol{f}_{i-1}$(第$i-1$个Token的激活分布),以更好地实现局部均衡
\begin{equation}\boldsymbol{\beta}_i = \boldsymbol{\beta}_{i-1} + \eta(\boldsymbol{f}_{i-1} - 1/n)\end{equation}
这个思路能够保持序列的因果性,同时也能保证实现序列级几乎绝对的均衡,但由于每步都要执行选Top-$k$并且根据结果$\boldsymbol{f}$更新偏置项,所以这本质上引入了一个非线性RNN。非线性RNN无法并行,因此可以预见序列长了会是一个瓶颈。当然我们也可以考虑按Chunk来更新(Mini-batch TTT)以提高效率,但这就略微显得不优雅了。
最优之解 #
接下来,本文所提的思路称为“Moving Quantile Balancing(MQB)”,顾名思义,这是在“(Quantile Balancing)QB”的基础上演化出来的。为此,我们先简单回顾一下QB。
按照笔者撰写的顺序,是先有《MoE环游记:6、最优分配促均衡》再有《MoE环游记:7、动态激活极简解》,但实际上后者概念上和方法上都简单得多,所以我们从后者讲起。还是给定$\boldsymbol{s}\in\mathbb{R}^{l\times n}$,我们引入偏置项$\boldsymbol{\beta}\in\mathbb{R}^n$,静态版的MoE是每个Token都激活$\boldsymbol{s}_i - \boldsymbol{\beta}$最大的$k$个Expert,动态激活是指只要$\boldsymbol{s}_i - \boldsymbol{\beta} > 0$的Expert都激活,数量不定。
为了同时保证负载均衡和控制平均激活数量为$k$,需要选择适当的$\boldsymbol{\beta}$。非常奇妙的是,在这个场景下,$\boldsymbol{\beta}$的最优解是可以精确表示出来的:
\begin{equation}\boldsymbol{\beta} = \mathop{\text{desc_sort}}(\boldsymbol{s}, \text{axis=0})_{[lk/n:lk/n+1]} = \mathop{\text{quantile}}(\boldsymbol{s}, 1-k/n, \text{axis=0})\end{equation}
也就是说,将$\boldsymbol{s}$沿着序列维度(当前是$\text{axis=0}$)从大到小排列,取第$lk/n$大的元素,便是$\boldsymbol{\beta}$的最优解,这也对应于“$1-k/n$分位数”。
实际上,这只不过是Expert Choice的另一种表示方式,我们知道,Expert Choice的问题是会破坏因果律(非Causal),这从它沿着序列维度去求$\boldsymbol{\beta}$也可以看出。如果我们是Encoder场景,那么这种非Casual的方案自然不是问题,但对于单向的自回归模型却不可取。
滑动分位 #
前面 @ChangJonathanC 的“测试时训练”方案给了笔者一些启发。我们可以沿着序列维度,逐Token地基于QB计算偏置项,由于QB能够直接基于$\boldsymbol{s}$把偏置项的最优解表示出来,而不用知道Expert激活情况,所以这带来了一些并行的可能性。
笔者最开始的想法是$\boldsymbol{\beta}_i = \mathop{\text{quantile}}(\boldsymbol{s}_{[:i]}, 1-k/n, \text{axis=0})$,即对所有不超过当前位置的Token分数算偏置项,那么每个位置都有自己的偏置项,并且QB的最优性保证了直至当前位置都是均衡的。由于它需要沿着序列维度递进地计算分位数,我们不妨称这种运算为“Cumulative Quantile”,相应的方案为“Cumulative Quantile Balancing(CQB)”。
CQB原理上是可行的,但由于Quantile无法增量更新,所以CQB每一步都要读完整的数据做Quantile计算,计算复杂度是线性增加的,总复杂度则是平方级。为了缓解这个问题,同时为了更好地体现出局部均衡,笔者的想法是设定一个窗口$w$,每个Token只在不超过$w$的窗口内求最优偏置项,即
\begin{equation}\boldsymbol{\beta}_i = \mathop{\text{quantile}}(\boldsymbol{s}_{[i-w:i]}, 1-k/n, \text{axis=0})\end{equation}
这样运算就从“Cumulative Quantile”变成了“Moving Quantile”,相应的方案便是“Moving Quantile Balancing(MQB)”的雏型。它跟SWA(Sliding Window Attention)很相似,复杂度是线性的,并且理论上也可以并行,之所以还是“雏型”,依然是因为Quantile无法增量更新,导致单步复杂度依然相对较高,仍需设法改进。
分桶估计 #
上一节所说的各种障碍,本质上都受限于“Quantile是非线性的,无法增量更新”,有没有一种可能,我们设法将它线性化呢?哪怕只是近似都好?很幸运,这里还真能做到!
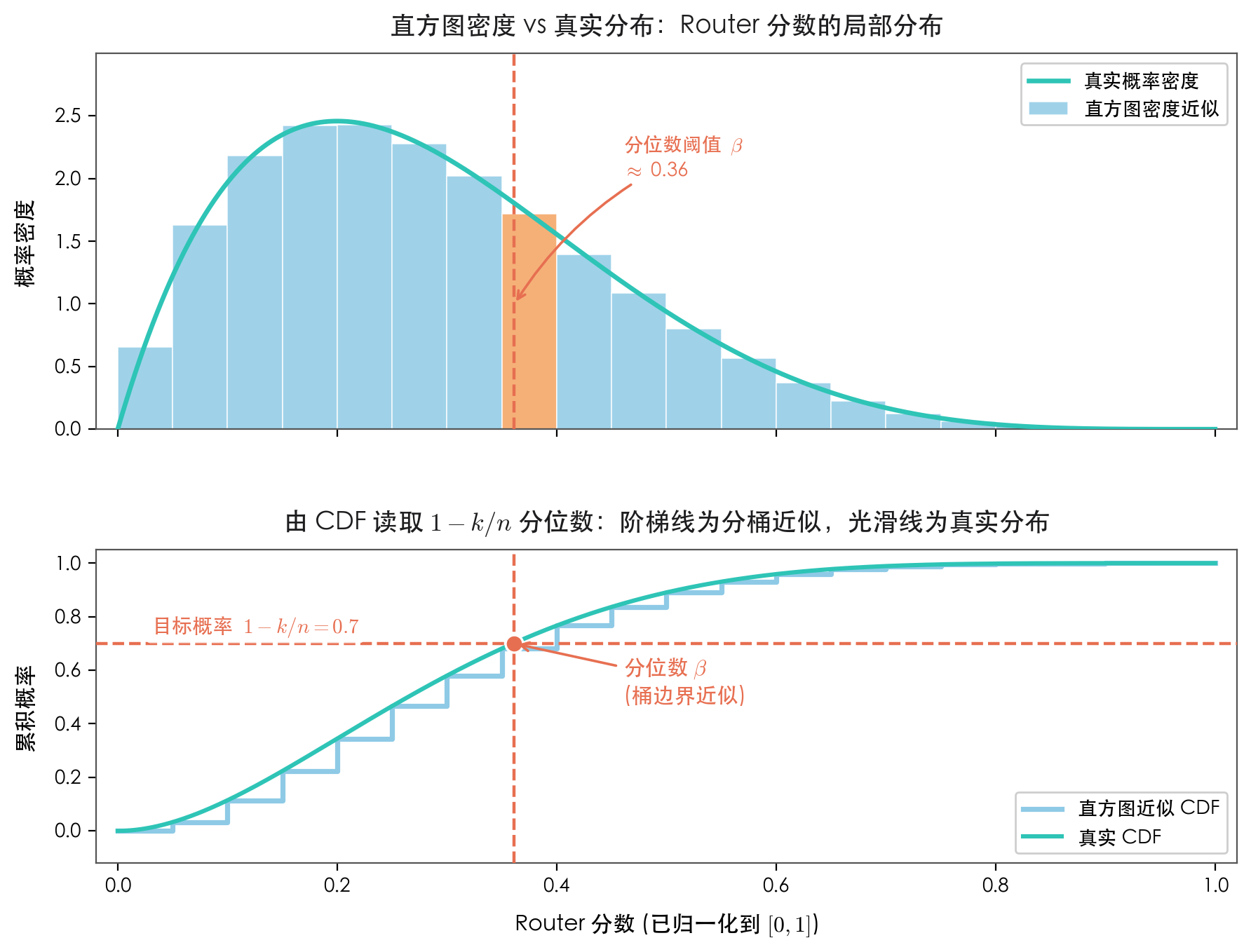
直方图近似估计分位数示意图
一个关键事实是:只要知道变量的分布,就可以通过累积概率求分位数,而分布是可以增量更新的!所以,这里的关键是将分位数的估计转化成分布的估计,对此我们使用分桶计数,也称为“直方图近似”。首先,假设Router分数$\boldsymbol{s}$都在$[0, 1]$内,这可以通过加Sigmoid等激活函数来保证;接着,将$[0, 1]$等分为$b$个桶,将$\boldsymbol{s}$的每个值离散化为一个整数,继而转化为对应的one hot向量。
这样,我们就得到了一个$l\times n\times b$的0/1数组,如果将它沿着序列维度$l$求平均,就可以得到每个Expert的分数分布(以$b$维向量表示),继而可以求每个Expert的分位数。不过,为了保证因果性,我们不能直接对整个序列平均,只能做类似“Cumulative Average”的操作,为了避免“Moving Quantile”的严格边界带来的麻烦,同时也使得整个过程更为“平滑”,这里我们选择做EMA。
也就是说,将$\boldsymbol{s}$分桶one hot化后,我们沿着序列维度做EMA,每个Token都能得到一个局部的分布,根据这个分布就可以求对应的$1-k/n$分位数,这就是MQB的关键变量$\boldsymbol{\beta}_i$。由于EMA这个操作是线性的、可并行的,因此我们就以一种相对高效的、Loss-Free的方式实现了序列级均衡,这便是最终版的MQB。
$$\begin{array}{|l|}
\hline
\text{Moving Quantile Balancing (MQB)} \\[4pt]
\hline
\text{输入: 打分矩阵 }\boldsymbol{s}\in [0,1]^{l\times n} \\
\text{输出: 校正后的打分矩阵 }\hat{\boldsymbol{s}}\in \mathbb{R}^{l\times n} \\[4pt]
\hline
\begin{array}{ll}
1: & \boldsymbol{h}_{i,j} = \mathop{\text{one_hot}}(\lfloor s_{i,j} \times b\rfloor)\in\{0,1\}^b \\
2: & \bar{\boldsymbol{h}}_{i,j} = \gamma\bar{\boldsymbol{h}}_{i-1,j} + (1-\gamma)\boldsymbol{h}_{i,j} \\
3: & m_{i,j}^* = \min\{m \,|\, \sum_{t=0}^m \bar{h}_{i,j,t} \geq 1 - \frac{k}{n}\} \\
4: & \beta_{i,j} =(m_{i,j}^* + 1/2) / b \\
5: & \hat{\boldsymbol{s}}_i = \boldsymbol{s}_i - \boldsymbol{\beta}_i,
\end{array} \\
\hline
\end{array}$$
一般情况 #
到目前为止,我们的讨论都是基于动态激活版MoE的,即激活$\boldsymbol{s}_i - \boldsymbol{\beta}_i > 0$的Expert,数目不定。从《MoE环游记:6、最优分配促均衡》我们知道,如果是Top-$k$版MoE,它的$\boldsymbol{\beta}$并没有简单的解析解,需要交替迭代。
那么Top-$k$版MoE又该如何以Loss-Free的方式去实现序列级负载均衡呢?实际上,MQB在动态激活下能够实现序列级均衡,表明它已经把Router局部的异常高峰“削平”了,这时候我们对$\boldsymbol{s}_i - \boldsymbol{\beta}_i$取Top-$k$,它也许是不均衡的,但这种不均衡至多是全局级别的,那么我们只需给它补上一步全局均衡的QB,就可以重新恢复均衡性。
也就是说,对于Top-$k$版MoE,我们的强制序列级均衡方案是MQB+QB,在$\boldsymbol{s}_i - \boldsymbol{\beta}_i$序列的基础上再做一次QB(当然换SignSGD也行),即可实现序列级负载均衡。但要注意,完美的序列级负载均衡往往会明显损伤效果,一般情况下全局均衡够用了,序列级均衡只是用来预防极端情况,所以施加程度不宜过重。
为了降低对主任务的影响,Aux Loss方案可以选择调低损失系数,而MQB则可以考虑将前后的分数做个加权平均:
\begin{equation}\lambda(\boldsymbol{s}_i - \boldsymbol{\beta}_i) + (1-\lambda)\boldsymbol{s}_i = \boldsymbol{s}_i - \lambda \boldsymbol{\beta}_i,\qquad \lambda\in[0, 1]\end{equation}
也就是说,通过引入$\lambda < 1$来削弱序列均衡的程度,然后在此基础上叠加QB来保证全局均衡(由于$\lambda < 1$是无法保证均衡的,所以这时候无论是动态版还是Top-$k$版都需要补上QB)。
其他细节 #
经过分桶后,MQB的核心运算也变成EMA,所以兜兜转转,我们又回到了EMA,形式跟 @ChangJonathanC 所提的第一种方案类似,不同的是EMA的对象。@ChangJonathanC 的方案是直接对$l\times n$大小的原始分数做EMA,MQB则是将它扩张成$l\times n\times b$后再做EMA。
这个变化有点像是线性注意力通过外积来扩大容量,能够记忆的信息更多,而且QB的最优性也保证了它能实现序列级均衡,不再停留在经验做法。另一点跟线性注意力的相似性是,EMA本质上也是个RNN,所以推理阶段要多存一个$n\times b$大小的State向量,实践发现$b=100$已经能取得不错的效果,所以这个大小的State应该尚可接受。
还需要指出的是,不管QB还是MQB,它们都只用于Expert的激活决策,最后乘上Expert的门控函数,还是基于减去偏置项之前的、原始的Router分数来计算,这是所有Loss-Free方案共同的特点,确保均衡干预项不直接改变MoE形式,以求对主模型的影响最小化。
最后,关于分桶方式,笔者目前的实验是通过Sigmoid激活然后$[0,1]$均匀离散化来分桶,而如何更精细地分桶,可能还有一定的实验空间,这些交给有兴趣的读者完成了。
实验结果 #
对于MQB,笔者简单做了些实验,配置是一个总参数量约3B、128选4的MoE模型,MQB的滑动平均系数为0.99、分桶数默认为100,用MaxVio作为负载均衡指标。由于第一层MoE是最不均衡的,所以下面我们都只演示第一层的效果。
首先是$\lambda=1$的完全体MQB:
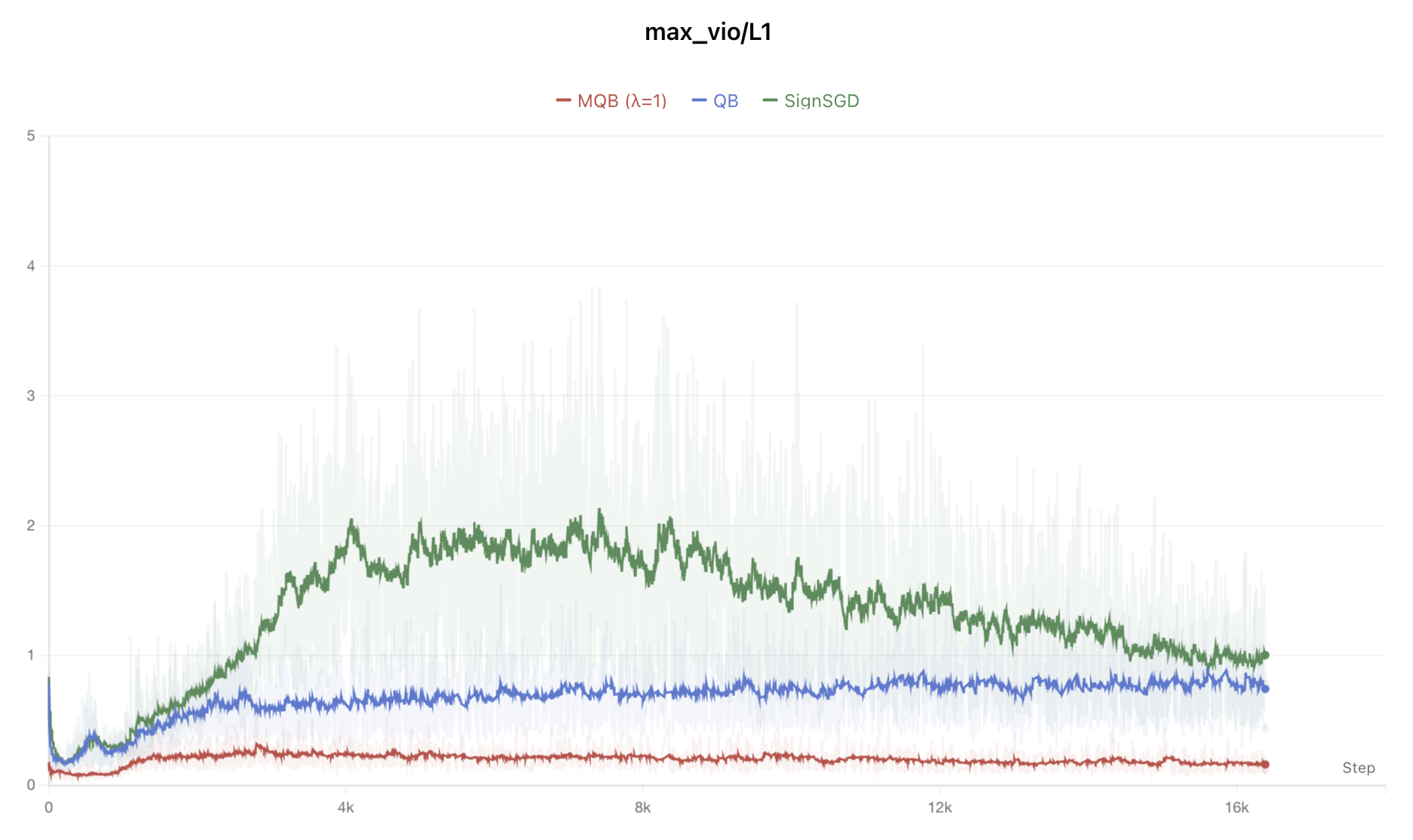
MQB(λ=1)与QB、SignSGD的效果比较
可见$\lambda=1$能实现非常完美的负载均衡,代价是Loss差了0.06,这是非常可观的掉点了,表明过于序列均衡是对效果不利的。但如果将$\lambda$调到0.3左右,那么Loss基本不掉,并且依然能促进负载均衡,如下图
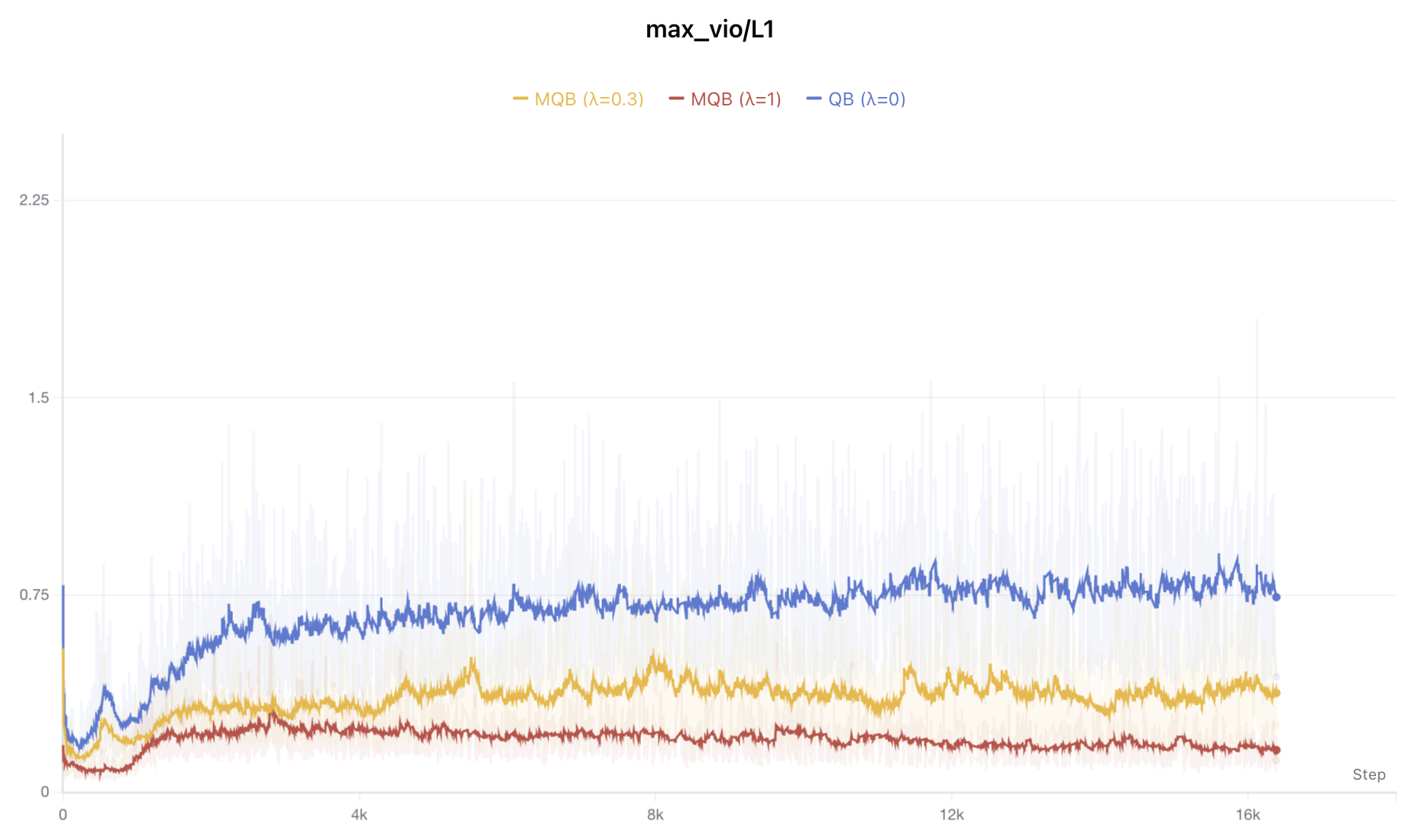
不同的λ对应的负载均衡情况
延伸思考 #
从上面的实验我们可以进一步确认,完美的序列级均衡($\lambda=1$)对效果损伤比较严重,如果取$\lambda=0.3$,那么能够大致保证效果无损,同时改善每一层的均衡情况。
总的来说,本文只是回答“怎么用Loss-Free的方式实现序列级负载均衡”,但是否需要序列级负载均衡、为什么需要序列级负载均衡、需要何种程度上的序列级负载均衡,对此我们无法给出标准答案。一个初步的理解是,序列级的极度不均衡,可能会对序列本身的效果有所影响(坍缩为一个小模型),所以希望鼓励一定程度的序列级均衡。
除了MQB外,其实还有一些别的方案也能Loss-Free地实现序列级均衡,比如我们在《DeepSeek V4的tid2eid是怎么来的?》所介绍的Hash Routing,也算是一种强制序列均衡的简单方案。但Hash Routing已经重新定义了路由形式,属于非常规路线。
MQB这种方案的价值在于,它更好地兼容常规的MoE形式,并且将“调节Aux Loss的系数”转化成了“调节一个可解释的局部偏置项”,让我们可以更直观地控制干预强度,同时可并行性也保证了效率。由于它只影响Router决策而不注入梯度,所以对主任务的效果影响也尽可能小。
文章小结 #
本文围绕“如何用Loss-Free方式实现序列级负载均衡”展开,从原本的Quantile Balancing(QB)出发,逐步推导出了一种名为Moving Quantile Balancing(MQB)方法,成功实现了这一目的。但序列级均衡是否真的必要、要做到什么程度,仍然是一个开放的问题。
转载到请包括本文地址:https://www.kexue.fm/archives/11760
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 22, 2026). 《MoE环游记:8、强制序列级均衡 》[Blog post]. Retrieved from https://www.kexue.fm/archives/11760
@online{kexuefm-11760,
title={MoE环游记:8、强制序列级均衡},
author={苏剑林},
year={2026},
month={May},
url={\url{https://www.kexue.fm/archives/11760}},
}

May 25th, 2026
苏神,如果只考虑原本的Quantile Balancing方法,这种分桶估计的方式是否也比之前文章提到的micro_batch求分位数再平均or梯度下降的方法更加准确高效呢
May 25th, 2026
苏神你好,“这个偏置项用SignSGD来更新。既然如此,我们可以模仿TTT的“测试时训练”思想,沿着序列维度逐Token地激活Expert,并根据已经激活的分布情况,更新这个偏置项。”这个思路对我有点启发,我是做边缘侧moe推理的,目前在探索moe能不能在受限内存下单batch激活计算。具体我再细读想象,但是有可能通过这根更新思路,维护受限内存的专家子集的更新方案,保持性能嘛。
受限内存的专家子集的更新是指显存无法放下所有专家,部分专家需要放在内存里,gpu算attn和moe的同时,有一个cache pool缓存多于topk的专家,这样命中的可以先算,没命中的从内存加载,配平好带宽的情况下也能拿到可用性能