






26
Jan
DeltaNet的核心逆矩阵的元素总是在[-1, 1]内
By 苏剑林 | 2026-01-26 | 3832位读者 | 引用从《线性注意力简史:从模仿、创新到反哺》中我们可以看到,DeltaNet的并行形式涉及到了形如$(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}$的逆矩阵。近日读者 @Arch123 提出,通过实验可观察到该逆矩阵的元素总是在$[-1, 1]$内,问是否可以从数学上证实或证伪它。
在这篇文章中,我们将通过两种不同的方式证明这个结论是严格成立的。
问题描述
首先,我们准确地重述一下问题。设有矩阵$\boldsymbol{K}=[\boldsymbol{k}_1,\boldsymbol{k}_2,\cdots,\boldsymbol{k}_n]^{\top}\in\mathbb{R}^{n\times d}$,其中每个$\boldsymbol{k}_i\in\mathbb{R}^{d\times 1}$是模长不超过1的列向量,$\boldsymbol{M}\in\mathbb{R}^{n\times n}$是一个下三角的掩码矩阵,定义为
\begin{equation}M_{i,j} = \left\{\begin{aligned} &1, &i \geq j \\ &0, &i < j\end{aligned}\right.\end{equation}
$\boldsymbol{I}$是单位阵,$\boldsymbol{M}^- = \boldsymbol{M} - \boldsymbol{I}$。我们要证明的是:
\begin{equation}(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}\quad\in\quad [-1, 1]^{n\times n}\end{equation}
23
Dec
为什么DeltaNet要加L2 Normalize?
By 苏剑林 | 2025-12-23 | 9589位读者 | 引用在文章《线性注意力简史:从模仿、创新到反哺》中,我们介绍了DeltaNet,它把Delta Rule带进了线性注意力中,成为其强有力的工具之一,并构成GDN、KDA等后续工作的基础。不过,那篇文章我们主要着重于DeltaNet的整体思想,并未涉及到太多技术细节——这篇文章我们来讨论其中之一:DeltaNet及其后续工作都给$\boldsymbol{Q}、\boldsymbol{K}$加上了L2 Normalize,这是为什么呢?
当然,直接从特征值的角度解释这一操作并不困难,但个人总感觉还差点意思。前几天笔者在论文《Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics》学习到了一个新理解,感觉也有可取之处,特来分享一波。
5
Oct
为什么线性注意力要加Short Conv?
By 苏剑林 | 2025-10-05 | 47110位读者 | 引用如果读者有关注模型架构方面的进展,那么就会发现,比较新的线性Attention(参考《线性注意力简史:从模仿、创新到反哺》)模型都给$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$加上了Short Conv,比如下图所示的DeltaNet:
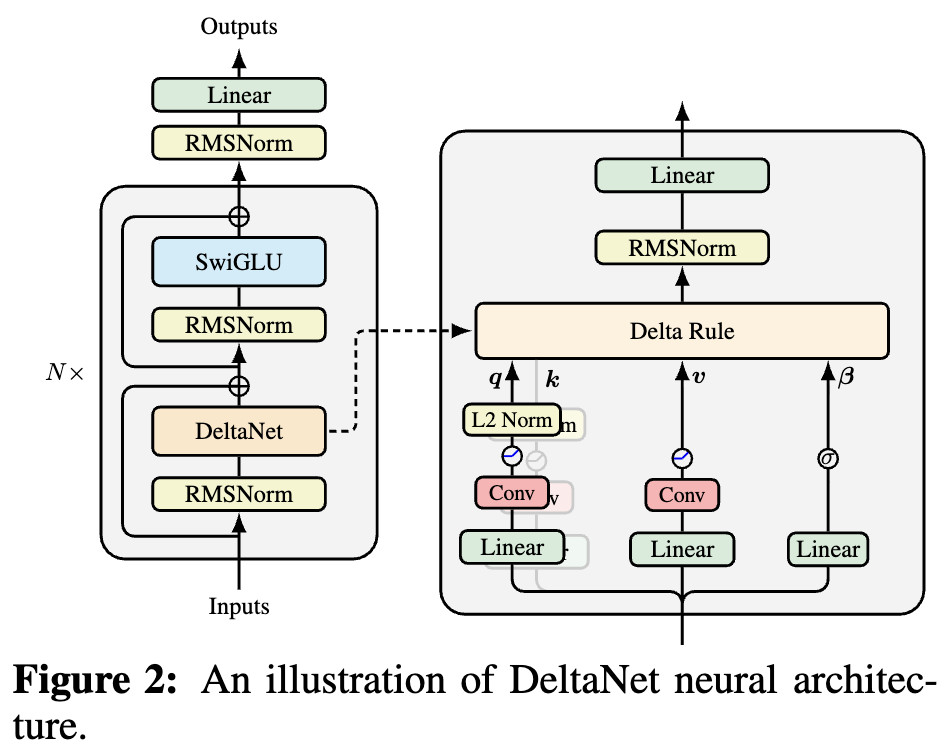
DeltaNet中的Short Conv
为什么要加这个Short Conv呢?直观理解可能是增加模型深度、增强模型的Token-Mixing能力等,说白了就是补偿线性化导致的表达能力下降。这个说法当然是大差不差,但它属于“万能模版”式的回答,我们更想对它的生效机制有更准确的认知。
接下来,笔者将给出自己的一个理解(更准确说应该是猜测)。
1
Jul
“对角+低秩”三角阵的高效求逆方法
By 苏剑林 | 2025-07-01 | 32056位读者 | 引用从文章《线性注意力简史:从模仿、创新到反哺》我们可以发现,DeltaNet及其后的线性Attention模型,基本上都关联到了逆矩阵$(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot\boldsymbol{M}^-)^{-1}$。本文就专门来探讨一下这类具有“对角+低秩”特点的三角矩阵的逆矩阵计算。
基本结果
我们将问题一般地定义如下:
给定矩阵$\boldsymbol{Q},\boldsymbol{K}\in\mathbb{R}^{n\times d}$和对角矩阵$\boldsymbol{\Lambda}\in\mathbb{R}^{n\times n}$,满足$n\gg d$,定义 \begin{equation}\boldsymbol{T} = \boldsymbol{\Lambda} + \boldsymbol{Q}\boldsymbol{K}^{\top}\odot\boldsymbol{M}^-\end{equation} 其中$\boldsymbol{M}^-=\boldsymbol{M} - \boldsymbol{I}$,矩阵$\boldsymbol{M}$定义为 \begin{equation}M_{i,j} = \left\{\begin{aligned} &1, &i \geq j \\ &0, &i < j\end{aligned}\right.\end{equation} 现在要求逆矩阵$\boldsymbol{T}^{-1}$,并且证明其复杂度是$\mathcal{O}(n^2)$。
20
Jun
线性注意力简史:从模仿、创新到反哺
By 苏剑林 | 2025-06-20 | 115893位读者 | 引用在中文圈,本站应该算是比较早关注线性Attention的了,在2020年写首篇相关博客《线性Attention的探索:Attention必须有个Softmax吗?》时,大家主要讨论的还是BERT相关的Softmax Attention。事后来看,在BERT时代考虑线性Attention并不是太明智,因为当时训练长度比较短,且模型主要还是Encoder,用线性Attention来做基本没有优势。对此,笔者也曾撰文《线性Transformer应该不是你要等的那个模型》表达这一观点。
直到ChatGPT的出世,倒逼大家都去做Decoder-only的生成式模型,这跟线性Attention的RNN形式高度契合。同时,追求更长的训练长度也使得Softmax Attention的二次复杂度瓶颈愈发明显。在这样的新背景下,线性Attention越来越体现出竞争力,甚至出现了“反哺”Softmax Attention的迹象。
27
Jun
重温SSM(四):有理生成函数的新视角
By 苏剑林 | 2024-06-27 | 30986位读者 | 引用在前三篇文章中,我们较为详细地讨论了HiPPO和S4的大部分数学细节。那么,对于接下来的第四篇文章,大家预期我们会讨论什么工作呢?S5、Mamba乃至Mamba2?都不是。本系列文章主要关心SSM的数学基础,旨在了解SSM的同时也补充自己的数学能力。而在上一篇文章我们简单提过S5和Mamba,S5是S4的简化版,相比S4基本上没有引入新的数学技巧,而Mamba系列虽然表现优异,但它已经将$A$简化为对角矩阵,所用到的数学技巧就更少了,它更多的是体现了工程方面的能力。
这篇文章我们来学习一篇暂时还声名不显的新工作《State-Free Inference of State-Space Models: The Transfer Function Approach》(简称RFT),它提出了一个新方案,将SSM的训练、推理乃至参数化,都彻底转到了生成函数空间中,为SSM的理解和应用开辟了新的视角
基础回顾
首先我们简单回顾一下上一篇文章关于S4的探讨结果。S4基于如下线性RNN
\begin{equation}\begin{aligned}
x_{k+1} =&\, \bar{A} x_k + \bar{B} u_k \\
y_{k+1} =&\, \bar{C}^* x_{k+1} \\
\end{aligned}\label{eq:linear}\end{equation}
20
Jun
重温SSM(三):HiPPO的高效计算(S4)
By 苏剑林 | 2024-06-20 | 60185位读者 | 引用前面我们用两篇文章《重温SSM(一):线性系统和HiPPO矩阵》和《重温SSM(二):HiPPO的一些遗留问题》介绍了HiPPO的思想和推导——通过正交函数基对持续更新的函数进行实时逼近,其拟合系数的动力学正好可以表示为一个线性ODE系统,并且对于特定的基底以及逼近方式,我们可以将线性系统的关键矩阵精确地算出来。此外,我们还讨论了HiPPO的离散化和相关性质等问题,这些内容奠定了后续的SSM工作的理论基础。
接下来,我们将介绍HiPPO的后续应用篇《Efficiently Modeling Long Sequences with Structured State Spaces》(简称S4),它利用HiPPO的推导结果作为序列建模的基本工具,并从新的视角探讨了高效的计算和训练方式,最后在不少长序列建模任务上验证了它的有效性,可谓SSM乃至RNN复兴的代表作之一。
基本框架
S4使用的序列建模框架,是如下的线性ODE系统:
\begin{equation}\begin{aligned}
x'(t) =&\, A x(t) + B u(t) \\
y(t) =&\, C^* x(t) + D u(t)
\end{aligned}\end{equation}
5
Jun
重温SSM(二):HiPPO的一些遗留问题
By 苏剑林 | 2024-06-05 | 39340位读者 | 引用书接上文,在上一篇文章《重温SSM(一):线性系统和HiPPO矩阵》中,我们详细讨论了HiPPO逼近框架其HiPPO矩阵的推导,其原理是通过正交函数基来动态地逼近一个实时更新的函数,其投影系数的动力学正好是一个线性系统,而如果以正交多项式为基,那么线性系统的核心矩阵我们可以解析地求解出来,该矩阵就称为HiPPO矩阵。
当然,上一篇文章侧重于HiPPO矩阵的推导,并没有对它的性质做进一步分析,此外诸如“如何离散化以应用于实际数据”、“除了多项式基外其他基是否也可以解析求解”等问题也没有详细讨论到。接下来我们将补充探讨相关问题。
离散格式
假设读者已经阅读并理解上一篇文章的内容,那么这里我们就不再进行过多的铺垫。在上一篇文章中,我们推导出了两类线性ODE系统,分别是:
\begin{align}
&\text{HiPPO-LegT:}\quad x'(t) = Ax(t) + Bu(t) \label{eq:legt-ode}\\[5pt]
&\text{HiPPO-LegS:}\quad x'(t) = \frac{A}{t}x(t) + \frac{B}{t}u(t) \label{eq:legs-ode}\end{align}
其中$A,B$是与时间$t$无关的常数矩阵,HiPPO矩阵主要指矩阵$A$。在这一节中,我们讨论这两个ODE的离散化。

最近评论