






2
Mar
MuP之上:3. 特殊情况特殊处理
By 苏剑林 | 2026-03-02 | 3180位读者 | 引用经过那么多篇相关博客的介绍,想必很多读者都对Muon优化器并不陌生——即便不清楚理论细节,应该也留下了一个“专为矩阵参数定制的优化器”的印象。然而,这个说法并不全对——比如对于输入端的Embedding层和输出段的LM Head来说,它们的参数虽然也都是矩阵,但并不适合用Muon(参考《Muon优化器指南:快速上手与关键细节》)。
为什么它们要被“区别对待”呢?本文将沿用首篇提出的三个稳定性指标,探讨不同类型的层的初始化规律及其对应的最速下降方向,从而回答这个问题。
前情回顾
在第一篇文章《MuP之上:1. 好模型的三个特征》中,我们提出了三个稳定性指标
23
Feb
MoE环游记:7、动态激活极简解
By 苏剑林 | 2026-02-23 | 4847位读者 | 引用上一篇文章《MoE环游记:6、最优分配促均衡》中,我们通过求解如下最优分配问题来实现负载均衡
\begin{equation}\max_{x_{i,j}\in\{0,1\}} \sum_{i,j} x_{i,j}s_{i,j} \qquad\text{s.t.}\qquad \sum_j x_{i,j} = k,\quad \sum_i x_{i,j} = \frac{mk}{n}\end{equation}
其中$\sum_j x_{i,j} = k$表示每个Token恰好激活$k$个Expert,而$\sum_i x_{i,j} = mk/n$表示每个Expert恰好被激活$mk/n$次。然而,仔细思考就会发现,其实前者对训练和推理都不是必要的,我们真正需要的是后者,它意味着“平均来说每个Token激活$k$个Expert”以及每个Expert的负载均衡,这足以达成MoE的目标,所以本文考虑更简化的问题
\begin{equation}\max_{x_{i,j}\in\{0,1\}} \sum_{i,j} x_{i,j}s_{i,j} \qquad\text{s.t.}\qquad \sum_i x_{i,j} = \frac{mk}{n}\label{eq:target-dyn}\end{equation}
22
Feb
MoE环游记:6、最优分配促均衡
By 苏剑林 | 2026-02-22 | 6836位读者 | 引用我们知道,负载均衡(Load Balance)是MoE架构中基本且关键的一环,直接影响模型的效率和性能。本系列已经有两篇文章介绍了两种实现负载均衡的主流思路,分别是《MoE环游记:2、不患寡而患不均》介绍的经典方案Aux Loss,以及《MoE环游记:3、换个思路来分配》中的由DeepSeek提出的Loss-Free方案。两者各有所长,亦各有局限。
本文将探讨第三种思路:最优分配,它将负载均衡视为等式约束下的线性规划问题。从最终形式上看,它仍属于Loss-Free,但基于截然不同的原理,提供了更准确且无超参的更新方式。
方法回顾
现有的两种方法中,Aux Loss的思路相对朴素,核心是“哪里不稳罚哪里”,通过正则项对负载不均施加惩罚。然而,Aux Loss有两个问题:首先,惩罚系数不好调,过大会干扰主Loss的优化,过小则均衡效果差;其次,Aux Loss的背后是STE(Straight-Through Estimator),这意味着它的梯度是次优的,它可能会带来负载均衡以外的未知影响。
15
Feb
MuP之上:2. 线性层与最速下降
By 苏剑林 | 2026-02-15 | 3314位读者 | 引用在上一篇文章《MuP之上:1. 好模型的三个特征》中,我们提出了前向稳定性、依赖稳定性、更新稳定性这三个核心指标,并给出了相应的数学定义。同时,我们提出以它们是否满足$\Theta(1)$来刻画一个模型的好坏,这将作为我们后续分析和计算的理论基石。接下来,我们将会把它们跟最速下降思想结合,给每个参数定制“稳中求快”的更新规则。
\begin{align}
&\text{前向稳定性:}\quad\max_{\boldsymbol{x}} \Vert \boldsymbol{f}(\boldsymbol{x};\boldsymbol{\omega})\Vert_{RMS} = \Theta(1) \label{eq:c1} \\[5pt]
&\text{依赖稳定性:}\quad\max_{\boldsymbol{x}_1,\boldsymbol{x}_2} \Vert \boldsymbol{f}(\boldsymbol{x}_1;\boldsymbol{\omega}) - \boldsymbol{f}(\boldsymbol{x}_2;\boldsymbol{\omega})\Vert_{RMS} = \Theta(1) \label{eq:c2} \\[5pt]
&\text{更新稳定性:}\quad\max_{\boldsymbol{x}} \Vert \boldsymbol{f}(\boldsymbol{x};\boldsymbol{\omega} + \Delta\boldsymbol{\omega}) - \boldsymbol{f}(\boldsymbol{x};\boldsymbol{\omega})\Vert_{RMS} = \Theta(1) \label{eq:c3}
\end{align}
我们以线性层作为第一个例子,其结果对部分读者来说应该不陌生,它就是去年逐渐兴起的Muon优化器。当然,我们的目的并不是重新发现Muon,而是展示从第一性原理出发来设计模型和优化器的过程,为我们后续处理其他参数提供统一的方法论。
26
Jan
DeltaNet的核心逆矩阵的元素总是在[-1, 1]内
By 苏剑林 | 2026-01-26 | 3832位读者 | 引用从《线性注意力简史:从模仿、创新到反哺》中我们可以看到,DeltaNet的并行形式涉及到了形如$(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}$的逆矩阵。近日读者 @Arch123 提出,通过实验可观察到该逆矩阵的元素总是在$[-1, 1]$内,问是否可以从数学上证实或证伪它。
在这篇文章中,我们将通过两种不同的方式证明这个结论是严格成立的。
问题描述
首先,我们准确地重述一下问题。设有矩阵$\boldsymbol{K}=[\boldsymbol{k}_1,\boldsymbol{k}_2,\cdots,\boldsymbol{k}_n]^{\top}\in\mathbb{R}^{n\times d}$,其中每个$\boldsymbol{k}_i\in\mathbb{R}^{d\times 1}$是模长不超过1的列向量,$\boldsymbol{M}\in\mathbb{R}^{n\times n}$是一个下三角的掩码矩阵,定义为
\begin{equation}M_{i,j} = \left\{\begin{aligned} &1, &i \geq j \\ &0, &i < j\end{aligned}\right.\end{equation}
$\boldsymbol{I}$是单位阵,$\boldsymbol{M}^- = \boldsymbol{M} - \boldsymbol{I}$。我们要证明的是:
\begin{equation}(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}\quad\in\quad [-1, 1]^{n\times n}\end{equation}
23
Dec
为什么DeltaNet要加L2 Normalize?
By 苏剑林 | 2025-12-23 | 9589位读者 | 引用在文章《线性注意力简史:从模仿、创新到反哺》中,我们介绍了DeltaNet,它把Delta Rule带进了线性注意力中,成为其强有力的工具之一,并构成GDN、KDA等后续工作的基础。不过,那篇文章我们主要着重于DeltaNet的整体思想,并未涉及到太多技术细节——这篇文章我们来讨论其中之一:DeltaNet及其后续工作都给$\boldsymbol{Q}、\boldsymbol{K}$加上了L2 Normalize,这是为什么呢?
当然,直接从特征值的角度解释这一操作并不困难,但个人总感觉还差点意思。前几天笔者在论文《Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics》学习到了一个新理解,感觉也有可取之处,特来分享一波。
5
Oct
为什么线性注意力要加Short Conv?
By 苏剑林 | 2025-10-05 | 47110位读者 | 引用如果读者有关注模型架构方面的进展,那么就会发现,比较新的线性Attention(参考《线性注意力简史:从模仿、创新到反哺》)模型都给$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$加上了Short Conv,比如下图所示的DeltaNet:
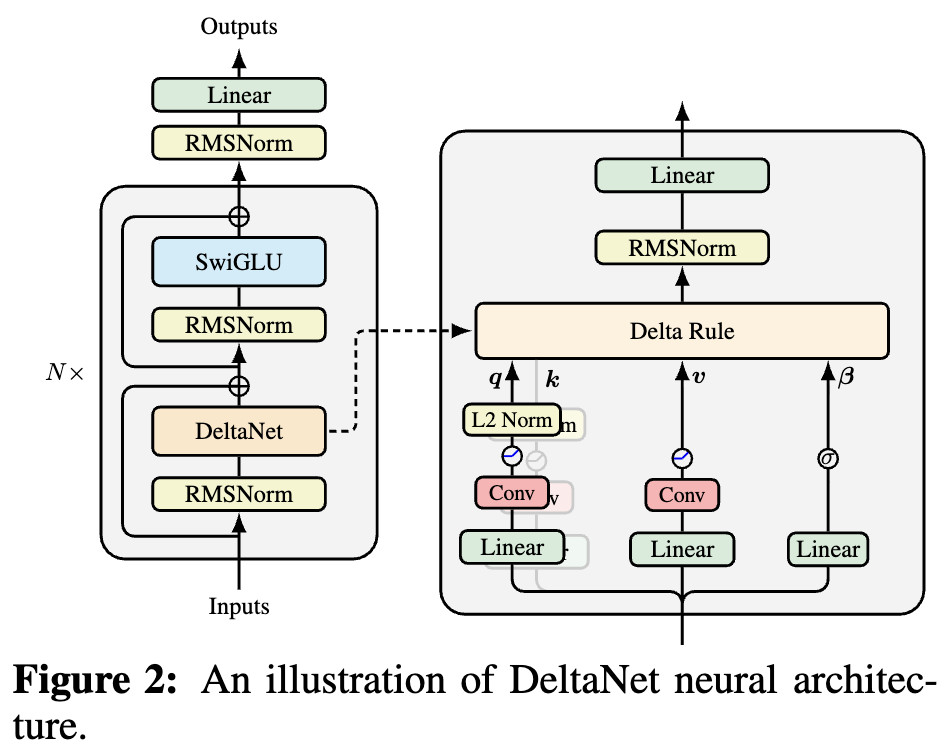
DeltaNet中的Short Conv
为什么要加这个Short Conv呢?直观理解可能是增加模型深度、增强模型的Token-Mixing能力等,说白了就是补偿线性化导致的表达能力下降。这个说法当然是大差不差,但它属于“万能模版”式的回答,我们更想对它的生效机制有更准确的认知。
接下来,笔者将给出自己的一个理解(更准确说应该是猜测)。
21
Jul
矩阵r次方根和逆r次方根的高效计算
By 苏剑林 | 2025-07-21 | 18358位读者 | 引用上一篇文章《矩阵平方根和逆平方根的高效计算》中,笔者从$\newcommand{mcsgn}{\mathop{\text{mcsgn}}}\mcsgn$算子出发,提出了一种很漂亮的矩阵平方根和逆平方根的计算方法。比较神奇的是,该方案经过化简之后,最终公式已经看不到最初$\mcsgn$形式的样子。这不禁引发了更深层的思考:该方案更本质的工作原理是什么?是否有推广到任意$r$次方根的可能性?
沿着这个角度进行分析后,笔者惊喜地发现,我们可以从一个更简单的角度去理解之前的迭代算法,并且在新角度下可以很轻松推广到任意$r$次方根和逆$r$次方根的计算。接下来我们将分享这一过程。
前情回顾
设$\boldsymbol{G}\in\mathbb{R}^{m\times n}$是任意矩阵,$\boldsymbol{P}\in\mathbb{R}^{n\times n}$是任意特征值都在$[0,1]$内的矩阵,上一篇文章给出:
\begin{gather}
\boldsymbol{G}_0 = \boldsymbol{G}, \quad \boldsymbol{P}_0 = \boldsymbol{P} \notag\\[6pt]
\boldsymbol{G}_{t+1} = \boldsymbol{G}_t(a_{t+1}\boldsymbol{I} + b_{t+1}\boldsymbol{P}_t + c_{t+1}\boldsymbol{P}_t^2) \label{eq:r2-rsqrt}\\[6pt]
\boldsymbol{P}_{t+1} = (a_{t+1}\boldsymbol{I} + b_{t+1}\boldsymbol{P}_t + c_{t+1}\boldsymbol{P}_t^2)^2\boldsymbol{P}_t \label{eq:r3-rsqrt}\\[6pt]
\lim_{t\to\infty} \boldsymbol{G}_t = \boldsymbol{G}\boldsymbol{P}^{-1/2}\notag
\end{gather}

最近评论