






31
Jan
Transformer升级之路:8、长度外推性与位置鲁棒性
By 苏剑林 | 2023-01-31 | 29628位读者 | 引用上一篇文章《Transformer升级之路:7、长度外推性与局部注意力》我们讨论了Transformer的长度外推性,得出的结论是长度外推性是一个训练和预测的不一致问题,而解决这个不一致的主要思路是将注意力局部化,很多外推性好的改进某种意义上都是局部注意力的变体。诚然,目前语言模型的诸多指标看来局部注意力的思路确实能解决长度外推问题,但这种“强行截断”的做法也许会不符合某些读者的审美,因为人工雕琢痕迹太强,缺乏了自然感,同时也让人质疑它们在非语言模型任务上的有效性。
本文我们从模型对位置编码的鲁棒性角度来重新审视长度外推性这个问题,此思路可以在基本不对注意力进行修改的前提下改进Transformer的长度外推效果,并且还适用多种位置编码,总体来说方法更为优雅自然,而且还适用于非语言模型任务。
12
Jan
Transformer升级之路:7、长度外推性与局部注意力
By 苏剑林 | 2023-01-12 | 59921位读者 | 引用对于Transformer模型来说,其长度的外推性是我们一直在追求的良好性质,它是指我们在短序列上训练的模型,能否不用微调地用到长序列上并依然保持不错的效果。之所以追求长度外推性,一方面是理论的完备性,觉得这是一个理想模型应当具备的性质,另一方面也是训练的实用性,允许我们以较低成本(在较短序列上)训练出一个长序列可用的模型。
下面我们来分析一下加强Transformer长度外推性的关键思路,并由此给出一个“超强基线”方案,然后我们带着这个“超强基线”来分析一些相关的研究工作。
思维误区
第一篇明确研究Transformer长度外推性的工作应该是ALIBI,出自2021年中期,距今也不算太久。为什么这么晚(相比Transformer首次发表的2017年)才有人专门做这个课题呢?估计是因为我们长期以来,都想当然地认为Transformer的长度外推性是位置编码的问题,找到更好的位置编码就行了。
28
Dec
Transformer升级之路:6、旋转位置编码的完备性分析
By 苏剑林 | 2022-12-28 | 27377位读者 | 引用在去年的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE),当时的出发点只是觉得用绝对位置来实现相对位置是一件“很好玩的事情”,并没料到其实际效果还相当不错,并为大家所接受,不得不说这真是一个意外之喜。后来,在《Transformer升级之路:4、二维位置的旋转式位置编码》中,笔者讨论了二维形式的RoPE,并研究了用矩阵指数表示的RoPE的一般解。
既然有了一般解,那么自然就会引出一个问题:我们常用的RoPE,只是一个以二维旋转矩阵为基本单元的分块对角矩阵,如果换成一般解,理论上效果会不会更好呢?本文就来回答这个问题。
指数通解
在《Transformer升级之路:4、二维位置的旋转式位置编码》中,我们将RoPE抽象地定义为任意满足下式的方阵
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\label{eq:re}\end{equation}
22
Dec
生成扩散模型漫谈(十五):构建ODE的一般步骤(中)
By 苏剑林 | 2022-12-22 | 19811位读者 | 引用上周笔者写了《生成扩散模型漫谈(十四):构建ODE的一般步骤(上)》(当时还没有“上”这个后缀),本以为已经窥见了构建ODE扩散模型的一般规律,结果不久后评论区大神 @gaohuazuo 就给出了一个构建格林函数更高效、更直观的方案,让笔者自愧不如。再联想起之前大神之前在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》同样也给出了一个关于扩散ODE的精彩描述(间接启发了上一篇博客的结果),大神的洞察力不得不让人叹服。
经过讨论和思考,笔者发现大神的思路本质上就是一阶偏微分方程的特征线法,通过构造特定的向量场保证初值条件,然后通过求解微分方程保证终值条件,同时保证了初值和终值条件,真的非常巧妙!最后,笔者将自己的收获总结成此文,作为上一篇的后续。
前情回顾
简单回顾一下上一篇文章的结果。假设随机变量$\boldsymbol{x}_0\in\mathbb{R}^d$连续地变换成$\boldsymbol{x}_T$,其变化规律服从ODE
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq-ode}\end{equation}
15
Dec
生成扩散模型漫谈(十四):构建ODE的一般步骤(上)
By 苏剑林 | 2022-12-15 | 34461位读者 | 引用书接上文,在《生成扩散模型漫谈(十三):从万有引力到扩散模型》中,我们介绍了一个由万有引力启发的、几何意义非常清晰的ODE式生成扩散模型。有的读者看了之后就疑问:似乎“万有引力”并不是唯一的选择,其他形式的力是否可以由同样的物理绘景构建扩散模型?另一方面,该模型在物理上确实很直观,但还欠缺从数学上证明最后确实能学习到数据分布。
本文就尝试从数学角度比较精确地回答“什么样的力场适合构建ODE式生成扩散模型”这个问题。
基础结论
要回答这个问题,需要用到在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中我们推导过的一个关于常微分方程对应的分布变化的结论。
考虑$\boldsymbol{x}_t\in\mathbb{R}^d, t\in[0,T]$的一阶(常)微分方程(组)
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
7
Dec
从局部到全局:语义相似度的测地线距离
By 苏剑林 | 2022-12-07 | 21720位读者 | 引用前段时间在最近的一篇论文《Unsupervised Opinion Summarization Using Approximate Geodesics》中学到了一个新的概念,叫做“测地线距离(Geodesic Distance)”,感觉有点意思,特来跟大家分享一下。
对笔者来说,“新”的不是测地线距离概念本身(以前学黎曼几何的时候就已经接触过了),而是语义相似度领域原来也可以巧妙地构造出测地线距离出来,并在某些场景下发挥作用。如果乐意,我们还可以说这是“流形上的语义相似度”,是不是瞬间就高级了不少?
论文梗概
首先,我们简单总结一下原论文的主要内容。顾名思义,论文的主题是摘要,通常我们的无监督摘要是这样做的:假设文章由$n$个句子$t_1,t_2,\cdots,t_n$组成,给每个句子设计打分函数$s(t_i)$(经典的是tf-idf及其变体),然后挑出打分最大的若干个句子作为摘要。当然,论文做的不是简单的摘要,而是“Opinion Summarization”,这个“Opinion”,我们可以理解为实现给定的主题或者中心$c$,摘要应该倾向于抽取出与$c$相关的句子,所以打分函数应该还应该跟$c$有关,即$s(t_i, c)$。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 20006位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
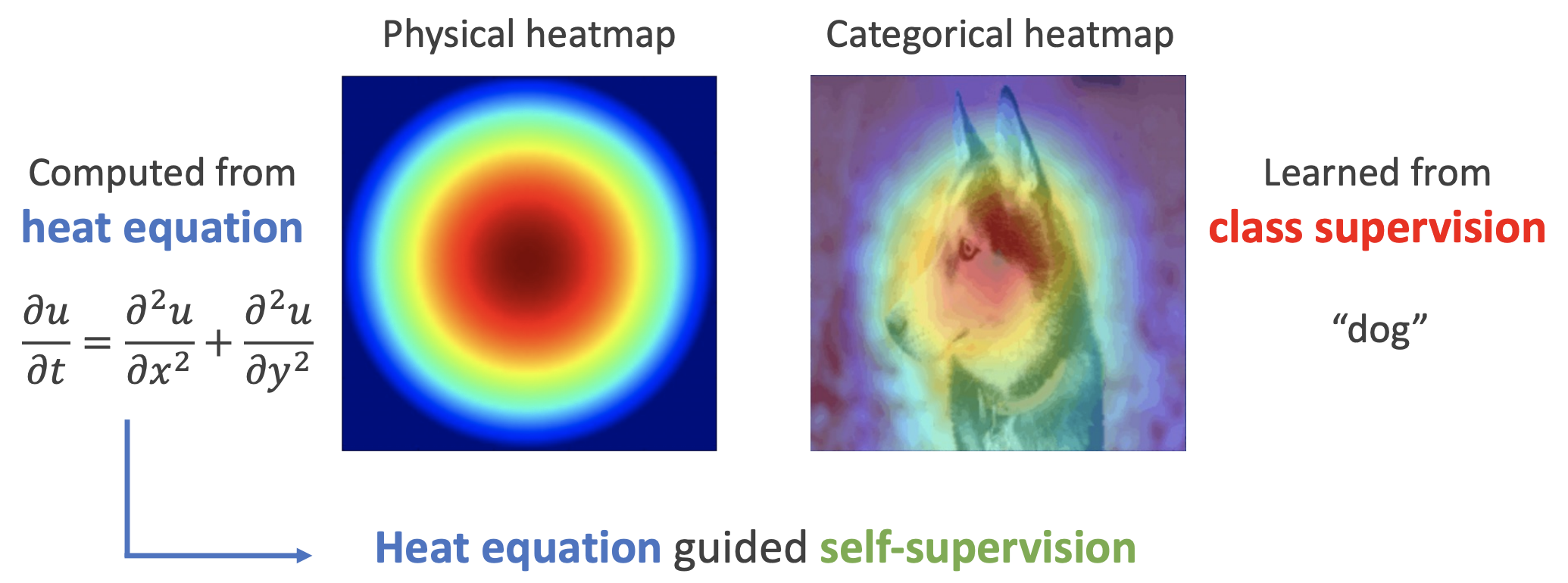
热方程的热力图(左)和视觉模型的热力图(右)
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 22096位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。

最近评论