






21
Feb
“闭门造车”之多模态思路浅谈(一):无损输入
By 苏剑林 | 2024-02-21 | 278248位读者 |这篇文章分享一下笔者关于多模态模型架构的一些闭门造车的想法,或者说一些猜测。
最近Google的Gemini 1.5和OpenAI的Sora再次点燃了不少人对多模态的热情,只言片语的技术报告也引起了大家对其背后模型架构的热烈猜测。不过,本文并非是为了凑这个热闹才发出来的,事实上其中的一些思考由来已久,最近才勉强捋顺了一下,遂想写出来跟大家交流一波,刚好碰上了两者的发布。
事先声明,“闭门造车”一词并非自谦,笔者的大模型实践本就“乏善可陈”,而多模态实践更是几乎“一片空白”,本文确实只是根据以往文本生成和图像生成的一些经验所做的“主观臆测”。
问题背景 #
首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗?
其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率$p(x_t|x_1,\cdots,x_{t-1})$,不论是最初的n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以,文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。
然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有VAE、GAN、Flow、Diffusion,还有小众的EBM、PixelRNN/PixelCNN等,这些方法的区分,并不是因为它们用了RNN、CNN或者Attention导致效果上的不同,而是建模理论就有根本差别。而造成图像生成手段多样化的根本原因,是对连续变量进行概率建模的困难性。
对于一个长度为$l$的句子$(x_1,x_2,\cdots,x_l)$,它的每个$x_t$都来自于一个有限的词表,因此$p(x_t|x_1,\cdots,x_{t-1})$本质上就是分类任务,在“神经网络的万能拟合能力 + Softmax”的组合下,理论上任何分类任务都可以精确建模,这就是文本生成背后的理论保证。然而,我们通常会将图像看成是连续型向量,那么对于图像来说,$x_t$就是一个实数,纵然我们也可以做同样的条件分解,那么又该如何建模$p(x_t|x_1,\cdots,x_{t-1})$呢?注意此时$p(x_t|x_1,\cdots,x_{t-1})$是一个概率密度,概率密度的必要条件是非负且积分为1:
\begin{equation}\int p(x_t|x_1,\cdots,x_{t-1}) dx_t = 1\end{equation}
除了正态分布,我们还能写出几个积分恒为1的函数呢?而能写出的函数如正态分布,并不足以拟合任意复杂的分布。说白了,神经网络是函数的万能拟合器,但不是概率密度的万能拟合器,这就是连续型变量做生成建模的本质困难,而图像生成的各种方案,本质上都是“各显神通”来绕过对概率密度的直接建模(除了Flow)。但离散型变量不存在这个困难,因为离散型概率的约束是求和为1,这通过Softmax就可以实现。
离散之路 #
这时候也许有读者会想:那么能不能将图像变成离散化的,然后套上文本生成的框架去做?确实可以,这是目前的主流思路之一(很可能没有“之一”)。
事实上,图像本来就是离散的,一幅$n\times n$大小的RGB图像,背后其实就是$3n^2$个0~255的整数,也就是说相当于长度为$3n^2$、vocab_size为256的句子。甚至往大了讲,计算机本质上是离散的,即它能表示的一切都是离散的,不管是文本、图像、语音还是视频,所以直接用它们的原始离散表示套用文本生成的框架在理论上是没有问题的,早些年的PixelRNN、PixelCNN等工作,就是直接在图像的像素空间上做自回归生成,之前我们在《为节约而生:从标准Attention到稀疏Attention》介绍的OpenAI的Sparse Transformer,主要实验之一也是Pixel级别的图像自回归。
然而,直接在像素空间上操作的最大问题是——序列太长,生成太慢。在多数应用场景中,图片分辨率起码要达到256以上才有实用价值(除非只是为了用于小图表情包的生成),那么就算$n=256$,也有$3n^2\approx 20\text{万}$,也就是说为了生成一张256大小的图片,我们需要自回归解码20万步!虽然近来Long Context技术有了长足的进步,但这个成本依然很奢侈,而且生成时间上也很难接受。
为此,一个很容易想到的思路是“先压缩,后生成”,即通过另外的模型压缩序列长度,然后在压缩后的空间进行生成,生成后再通过模型恢复为图像。压缩自然是靠AE(AutoEncoder),但我们想要的是套用文本生成的建模方式,所以压缩之后还要保证离散性,这就需要VQ-VAE,以及后来的VQ-GAN,其中VQ还可以替换为近来的FSQ。跟文本的Tokenizer类似,VQ-VAE/GAN就相当于“图像Tokenizer”的角色,它保持了编码结果的离散性,但序列长度明显缩小(比如分辨率降低为$1/4$,那么就是$3n^2\to (n/4)^2$,缩小48倍),并可以通过相应的Decoder恢复为原始图片(DeTokenize)。基于“图像Tokenizer”这个思路的多模态工作已经有很多,比如最近的LWM和AnyGPT。
不管原始的像素空间还是在压缩后的编码空间,它们都有一个共同的特点——都是二维特征,换句话说,文本只有左右一个维度,而图像则有左右、上下两个问题,那么在进行自回归生成的时候,就需要人工设计生成方向,比如先左右后上下、先上下后左右、从中心逆时针到四周、按照到左上角的距离排序等等。不同的生成方向可能会明显影响生成效果,这就引入了额外的超参,并且由于不够端到端而显得不够优雅。针对这个问题,我们可以用Cross Attention的方式对二维特征进行组合,输出只有单一方向的编码结果,相关工作可以参考《Planting a SEED of Vision in Large Language Model》。
压缩损失 #
看上去通过“图像Tokenzier”的方式,多模态生成已经“迎刃而解”?不然,问题才刚刚开始。
诸如VQ-VAE、VQ-GAN的图像Tokenzier的最大问题在于,为了明显提高生成速度,缩短序列长度,对编码分辨率做了高度压缩(主流的是$256\times 256\to 32\times 32$甚至$256\times 256\to 16\times 16$),这导致了图像信息的严重损失。为了直观地感知这一点,我们可以参考SEED一文的重构效果:

SEED的重构效果
可以看到,虽然重构图像确实很清晰,并且也基本保持了输入图像的整体语义,但局部细节完全不同,这意味着不可能基于该图像Tokenizer完成任意图文混合任务(比如OCR)。
进一步地,我们简单算一笔信息账,就能更清楚地知道信息损失有多严重了。首先,参考《Generating Long Sequences with Sparse Transformers》的实验结果,我们可以知道ImageNet-64的平均信息熵是3.44比特/字节,当时的模型还不够大,理论上增大模型这个数字还可以进一步降低,我们就当它是3比特/字节,那么一个64*64的ImageNet图像,平均的总信息熵是$64\times 64\times 3\times 3$比特;接着,我们知道vocab_size为$V$的词表,每个token的平均信息熵是$\log_2 V$比特,如果要想将编码长度压缩为$L$,并且实现无损压缩,那么至少有
\begin{equation}L\times \log_2 V \geq 64\times 64\times 3\times 3\end{equation}
如果$L=1024=32\times 32$,那么至少有$V\geq 2^{36}\approx 7\times 10^{10}$,如果$L=256=16\times 16$,那么更是至少要$V\geq 2^{144}\approx 2\times 10^{43}$!很明显当前各种图像Tokenizer的codebook大小,都没有达到如此逆天的量级,所以结果必然是严重的信息损失!
一个自然的质疑是:为什么必须无损呢?确实,人也做不到无损,甚至人对图像的理解,信息损失可能比图像Tokenizer更严重。但问题是,模型的最基本要求是跟人类自己的认知对齐,换句话说,有损压缩没问题,但至少对人来说是无损,就好比丢掉红外光和紫外光,对人眼是完全无损的一样。然而,“对人无损”本身是一个很宽泛的概念,没有可计算的指标,VQ-VAE直接用L2距离去重构图像,由于信息损失,模糊是必然的,VQ-GAN补充了GAN损失,提高了清晰度,但也只能大体上保持全局的语义,无法完全对齐人的标准。更何况,谁也不知道人什么时候会提出新的更依赖于细节的图像任务,因此从通用智能的角度来看,无损压缩是必然的最终选择。
由此可见,在一个真正通用的多模态模型中,图像部分必然要比文本部分要困难得多,因为图像的信息量远大于文字。但其实人类自己创造的图像(比如画画)也不会比文字(比如写作)复杂多少,真正复杂的图像,是直接采集自大自然的照片。所以归根结底,文字只是人类的产物,而图像是大自然的产物,人不如自然聪明,所以文字也不如图像难,而真正通用的人工智能,本就是要往全面碾压人类的方向走的。
扩散模型 #
言归正传。就当前的图像生成技术来说,如果限定无损压缩,那么要不就回到像素空间做自回归,但正如前述所分析的,这样的生成速度难以接受,所以剩下的唯一选择就是重新回到连续空间,即将图像视为连续型向量,并且在无损压缩的限定下,唯二的选择就是Flow模型和扩散模型了。
Flow本身设计上就是可逆的,扩散模型也可以导出可逆的ODE方程,它们都是将标准高斯分布映射为目标分布,这意味着它们有足够的熵源。离散型和连续型生成有所不同,离散型自回归生成的熵源是seqlen和vocab_size,而vocab_size的贡献是对数增长的,所以主要靠seqlen,但是seqlen等价于成本,所以离散型的熵源是昂贵的;基于变换的连续型生成的熵源是高斯噪声,原则上可以无穷无尽,是廉价且可并行的。不过Flow为了保证每一层的可逆性,对架构做了明显修改,很可能会明显影响效果上限(没有直接证据,但Flow模型确实没做出过惊艳的生成效果就是了),因此剩下的唯一选择就是扩散模型了。
注意扩散只是图像生成方案的选择,对于图像理解,从无损的角度来说,任何编码手段都有失真的风险,所以最保证输入肯定就是原始图像了。因此,最保险的方式,应该是以Patch的方式直接输入原始图像,即类似Fuyu-8b的处理方式:
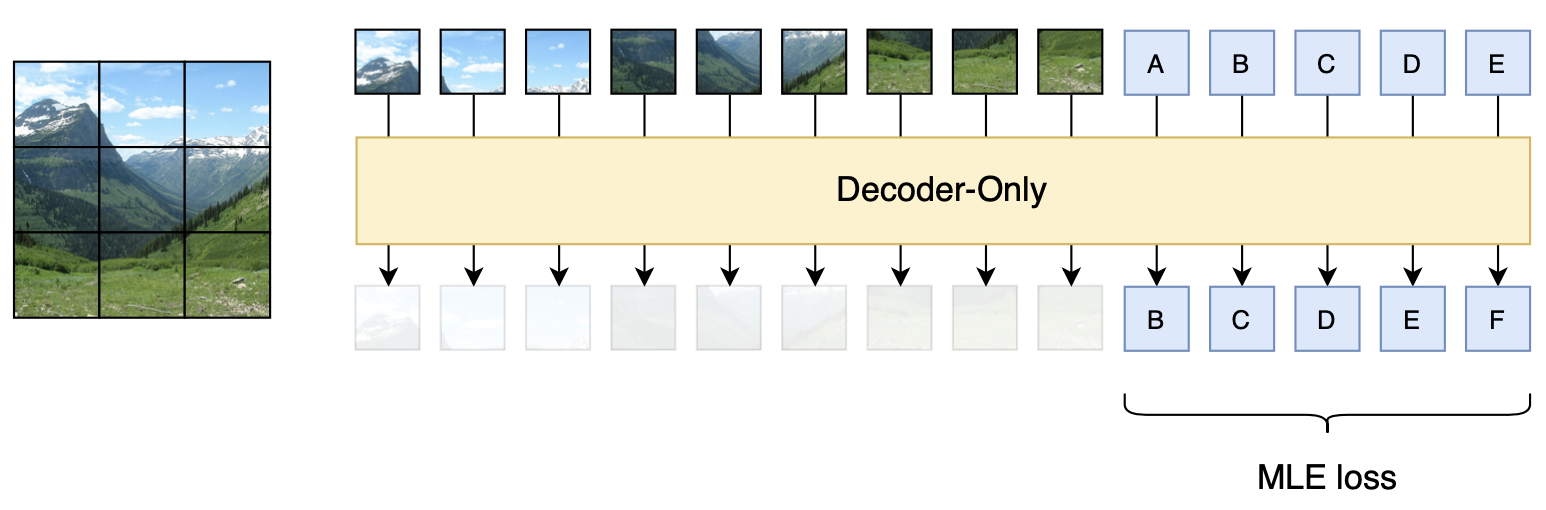
Fuyu-8b的模型示意图
但是Fuyu-8b只是多模态输入,输出还是单模态的文本。如何给它补上图像生成能力呢?考虑到扩散模型在训练阶段就是一个去噪任务,所以一个或许可行的做法是:
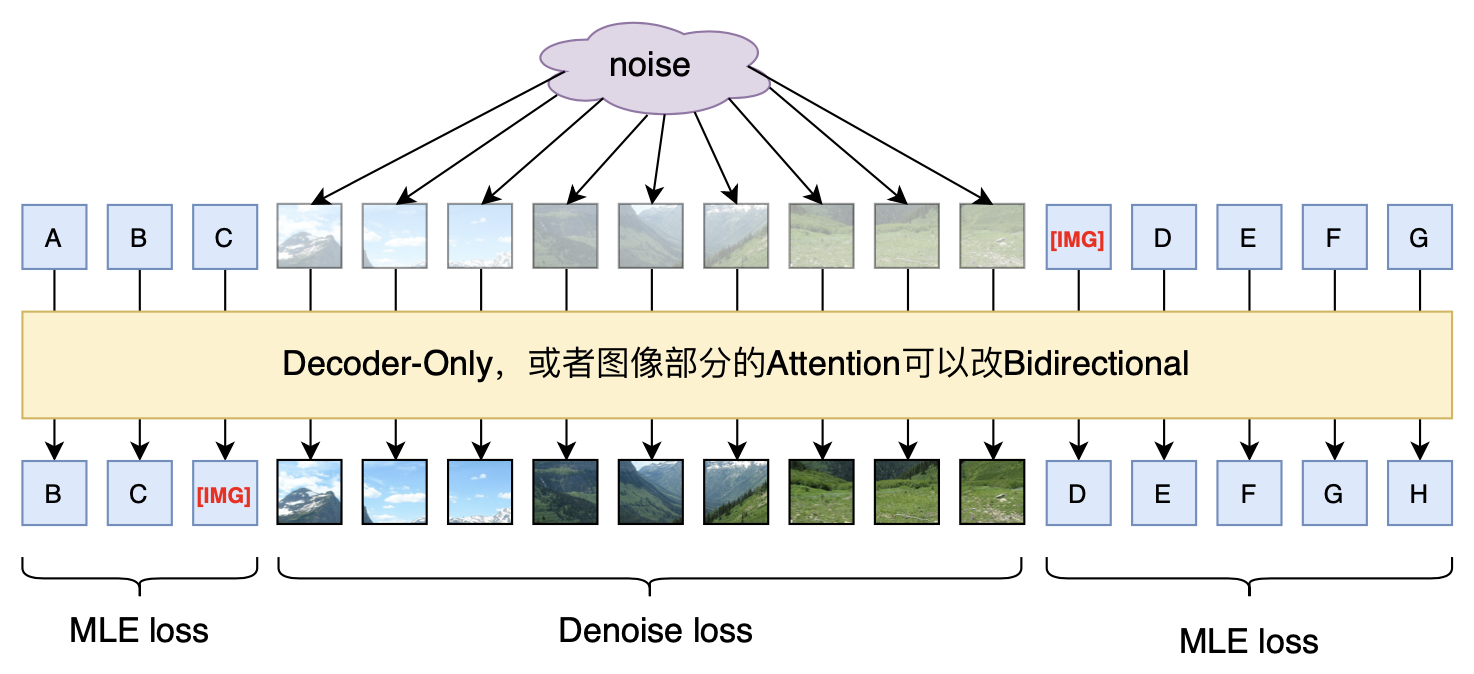
个人想象中的多模态生成做法
训练阶段,输入文本和加噪的图像,文本的训练目标就是预测下一个token,图像的训练目标就是预测原图(或者噪声);预测结果,文本部分还是token by token地递归,直到预测出[IMG],然后就并行输入若干个噪声向量,按照扩散模型的方式进行采样图像。注意图像生成部分是并行的,所以原则上不Decoder-Only更好,因为如果Decoder-Only的话,就需要人为指定排序了,不同的排序可能会明显影响效果。在当前扩散模型的加速采样技术下,基本上10个steps就可以完成图像的生成,因此生成速度是可以接受的。
(2024.08.26更新:Meta的新出的Transfusion跟上述方案基本一样,只是图片多加了一步Latent Encoder,效果颇佳;此外稍晚一点的Show-o也大同小异,差别是将Diffusion也离散化了。)
Patch输入 #
上述做法的一个关键是用到了Patch-based的扩散模型,所以最基本的是要验证这样的扩散模型设计是否可行(因为之前有说法是扩散模型本身非常依赖于已有的U-Net架构)。为此,笔者自己做了一些实验,也顺手调研了一些文献,下面总结一下自己的初步结论。
根据搜到的资料,最早尝试通过“Patch输入+Transformer”的组合做扩散模型的工作,应该是《All are Worth Words: A ViT Backbone for Diffusion Models》和《Scalable Diffusion Models with Transformers》。两篇论文大致同期,并且做法也大同小异,前者(U-ViT)主要强调了U-Net中的“Long skip connection”的作用,后者(DiT)则强调了将扩散模型的时间$t$和条件标签$y$以adaLN的方式融入模型的必要性。不过,只有U-ViT尝试了直接以原始图像的Patch作为输入的做法,并且分辨率也只做到了64*64,对于256*256和512*512分辨率的图像,不管是U-ViT还是DiT,都是在LDM的自编码器降维后的特征空间进行扩散的,这确实也是目前的主流做法,但跟前面说的一样,这种程度的压缩都伴随着严重的信息损失,很难说是真正通用的特征。
直接用原始图像的Patch而不是预训练的编码器特征作为输入,还有一个好处是避免造成特征间的孤立。比如,当我们需要同时输入两幅图像$I_1,I_2$的时候,基于编码器特征的通常做法是将$encoder(I_1),encoder(I_2)$输入到模型中,但问题是$encoder$本身就对图片内的语义做了一层交互,输入$encoder(I_1),encoder(I_2)$的话,$I_1,I_2$之间就欠缺了这一层交互,这就是图片间的特征孤立问题,更多细节可以参考《Browse and Concentrate: Comprehending Multimodal Content via prior-LLM Context Fusion》。所以,倒不如文本、图像都直接输入原始形式,将所有交互都交给多模态模型自行决定,这样就不存在这个隔阂了。
当然,直接输入原始图像的Patch的做法没有成为主流,背后必然有其困难之处,笔者也自行实验了一下。实验任务是CelebA-HQ的扩散生成,分辨率为64*64和128*128,分别reshape为16*16*48和16*16*192后投影到模型中;模型就是一个普通的Pre Norm的Transformer,没有Long skip connection,模型主干是GAU而不是MHA;位置编码是2D-RoPE,时间Embedding直接加到Patch输入熵。代码可以参考:
笔者的实验结果显示,不管是64*64还是128*128分辨率,它们确实都可以正常收敛,最终可以生成跟普通U-Net差不多的效果(没算FID,纯肉眼),但是需要训练更多的步数才收敛,比如都是单卡A800训练,128*128分辨率下普通U-Net大概1~2天就训出大致可看的结果,基于Transformer的架构则需要10多天才勉强可看。究其原因,大概是没有了CNN的Inductive Bias,模型需要花更多的训练步数才能学会适应图像的先验吧。不过对于多模态大模型来说,这大概不是什么问题,因为LLM所需要的训练步数本来就足够多。
文章小结 #
本文介绍了笔者关于多模态模型设计的构思——直接以原始图像的Patch作为图像输入,文本部分还是常规预测下一个Token,图像部分则用输入加噪图像来重构原图,这种组合理论上能以最保真的方式实现多模态生成。初步来看,直接以原始图像的Patch作为输入的Transformer,是有可能训练出成功的图像扩散模型的,那么这种扩散与文本混合的模型设计,也就有成功的可能了。当然,这只是笔者关于多模态路线的一些很潦草的想法,大部分没有经过实践验证,请大家斟酌阅读~
转载到请包括本文地址:https://www.kexue.fm/archives/9984
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Feb. 21, 2024). 《“闭门造车”之多模态思路浅谈(一):无损输入 》[Blog post]. Retrieved from https://www.kexue.fm/archives/9984
@online{kexuefm-9984,
title={“闭门造车”之多模态思路浅谈(一):无损输入},
author={苏剑林},
year={2024},
month={Feb},
url={\url{https://www.kexue.fm/archives/9984}},
}

February 21st, 2024
DiT好像没通过encoder降维、是patchfiy输入的。
降维了 代码有写 文章也有体现
有。
第3.2节 Patchify 那里,它说“The input to DiT is a spatial representation z (for 256 × 256 × 3 images, z has shape 32 × 32 × 4)”,这就显然不可能通过patch + reshape实现。
第4节的 Diffusion 那里,它说“We use an off-the-shelf pre-trained variational autoencoder (VAE) model [30] from Stable Diffusion [48]. The VAE encoder has a downsample factor of 8—given an RGB image x with shape 256 × 256 × 3, z = E(x) has shape 32 × 32 × 4.”
February 21st, 2024
图像视为连续变量这里怎么理解
就是图像的每个分量被视为一个实数而不是离散的整数,整个图像被视为一个实数的向量,为了描述它的分布,需要用到概率密度函数而不是概率。
February 22nd, 2024
[...]Read More [...]
February 22nd, 2024
DiT的实验结果显示把condition直接拼接到noisy patch上是效果最差的吧,adaLN>cross attn>拼接。
这种多模态架构训练过程好像会有一定冗余,一条数据样本,文本部分的loss一遍forward就够了,但是图片的denoise需要迭代很多遍。
这里说的是扩散中的时间$t$和类别标签$y$,这两个貌似就是直接拼起来的,至于adaLN,应该是指文本条件?
DiT对比了几种condtioning的方式,你设想的这种结构应该是DiT说的`In-context conditioning`方式,即把条件变成token拼接到input sequense里。但是它的效果比较差,不如cross attention或者adaLN-Zero。
我说的是$y$和$t$啊,这在它的结构图是明确拼接的,你说的adaLN是conditioning那部分吧?
苏神,在DiT的adaLN里conditioning就是y+t,这里图像生成貌似并没有额外的文本条件输入。
那它的示意图是故意用来误导人的?
左边的整体图和右边的细节图都表示了DiT Block接收两部分输入(x和conditioning),可能是由于没有把t和y之间的加操作表示清楚,导致了一些歧义吧,不过看源码还是挺清晰的~
https://github.com/facebookresearch/DiT/blob/main/models.py#L243
我努力转换了一下对这个示意图的理解,大概明白你的意思了,已经更正,谢谢不厌其烦的指正。
现在几个开源的效果不错的DiT如pixart、hunyuanDit、LuminaT2X基本都是这么做的:time条件用AdaLN注入,文本条件用cross attention注入。
SD3的MMDit有点不一样,有点类似Encoder-Encoder结构,一个文本encoder加一个图片encoder,两边可以相互cross attention。但本质还是俩transformer。感觉统一拼成一个长串输入一个decoder-only的transformer还比较难,不知道一个统一的transformer啥时候才能出现
静观其变吧,还有很多问题需要解决,目前的很多多模态模型都只是在有损的情况下强行糅合,用我们leader的话说,就是400度近似的人不戴眼镜看世界。
February 22nd, 2024
苏神看过Emu2的方案吗?也是统一的多模态生成模型,文本token和image feature拼接输入decoder-only transformer,文本token计算交叉熵loss,图片计算回归loss。
他使用sdxl作为图片的decoder,图片的重构效果挺好的,细节很一致。甚至对于英文文本也能比较好的重构,但中文就完全不行了。
对了,忘记提一嘴Emu2。Emu2直接MSE回归图像特征,然后将这个特征作为条件,另外训练了扩散模型生成图片的,所以它生成图片的方式还是扩散。
另外,它图片encoder用的是EVA-02-CLIP-E-plus,有两个特点:1、参数量有5B,远远大于其他LDM用的VAE参数量,所以可以保留更多的细节;2、CLIP本身就经过图文的监督对齐,因此其特征可以保留较多的文字细节也不意外。
是的,绝大部分的多模态LLM使用的visual encoder都是clip encoder,我没看到用VAE encoder的。感觉还是现有的pretrain VAE参数量太小,性能太弱了。Emu2也不用VAE encoder而只用decoder。
clip需要监督训练,感觉scaling能力也终究会受限。
February 22nd, 2024
你上面提到:「神经网络是函数的万能拟合器,但不是概率密度的万能拟合器」,不過GAN似乎就是一種概率密度擬合的方式?其實在diffusion出來之前,最被看好的是GAN。GAN是一步直接生成影像,所以沒有離散化的問題。
我認為diffusion其實也是一種離散化,只是他的離散化體現在每個去噪的step上。每個step都生成一個有噪聲版本的x,只是噪聲慢慢減少而已。所以你也可以說diffusion 實際上建模了:
$$\int p(x_t|x_1,\cdots,x_{t-1}) dx_t = 1$$
其中$t$ 為 step數。
至於 patchify,我認為比較像是為了融合當前在文字與影像生成最優的兩個模型,Transformer 與 diffusion,所做的一個妥協。因為相比將連續的影像離散化,文字序列的連續化可能是更加困難的。在stable diffusion中,就是把文字轉成連續的 embedding 作為condition 進行影像生成。但是這種做法難以做到像LLM 一樣理解複雜的指令。為了讓文字生成圖片更加彈性,在 Transformer 之上整合影像生成應該是更加容易的。
既然diffusion model已經可以生成一整張圖了,那麼生成一小塊patch 應該不難。所以問題變成要如何讓每一個生成的patch 之間是語義連貫的,有順序關係的。而語義跟順序這件事情其實Transformer 都已經做得很好了,因為既然Transformer 已經可以根據上下文,按照正確的順序輸出語意連貫的文字,那麼按照正確的順序輸出連貫的圖片patch 應該也是很容易的。所以兩者結合下,就能輸出組合起來是連貫的影像patch。
另外你提到「直接输入原始图像的Patch」,那麼想請問你要怎麼加入position embedding呢?直接加在原始圖片patch上?若經過一層 encoder 後再加上 position embedding 不是更合理嗎?雖然你說直接使用原始影像patch可以「避免造成特征间的孤立」,但仔細思考,patch之間最重要的是甚麼?我認為是空間位置,而若都按照固定順序組合patch,Transformer 結合 position embedding 就足以決定每個patch之間的空間關係。空間關係決定好後,每個patch的內容就根據該位置預期出現甚麼來決定。比方說畫面上方是天空,下方是陸地,那麼輸出的上方的patch可能就是天空的一小部分,下方的patch就都是陸地的一小部分。至於patch與patch之間的接縫邊緣,可以透過 self-attention 自我交互達到一致。
所以直接輸入原始影像patch可能未必比較好。因為我們的目標是按指令生成,而非100%還原圖片。用原圖交互,或許能保留更多像素級特徵,但生成任務畢竟不是還原,丟掉一些細節資訊,反而能讓模型學會自動補上合理細節,進而生成不同於原始但合理的影像。
BTW, 在 《Scalable Diffusion Models with Transformers》 這篇,實驗顯示 patch size 越小,生成的圖片品質越好。若 patch size 為 2px X 2px,可以說每個patch幾乎沒有包含甚麼整體的訊息,但結果卻是更好,表明Transformer 有能力將像素級別的patch 用全局一致的方式組合起來,應該不會有你說的「造成特征间的孤立」。
另一方面,若你的假設是對的,直接用原圖patch 比 encoder 降維後更少訊息損失,那麼至少在patch size很小的情況下,應該是沒有有損失;而在patch size較大的情況,encoder 降維造成的損失較大,所以實驗上顯示細節較差。但我認為這跟embedding size有關。在token embedding size固定的情況下,一個patch 能夠encode的訊息量就固定了。實驗顯示 embedding size 有一定影響,但 patch size 影響似乎更大。不管embedding size多大,patch size 越小總是越好的。這可能表示現有的 linear layer encoder 對於 encode 細節並不擅長。若想一次輸入更大的 patch,可能要往如何改進encoder的方式,讓他更有效的encode細節。我認為,在 encode patch的方式,或許用CNN 更有效。
我不知道你有没有看错,特征孤立是encoder造成的,导致不同图片之间少了一层交互,不是像素级别的patchify造成的。
第二段评论我也没太看懂,encoder跟patchify无关的,你是不是将两者混淆了。patchify是指直接将原始图像分patch,然后reshape + dense后就直接传入到transformer中;encoder是指完整原始图像输入进去得到输出的特征,然后传入到transformer中。不是说先patchify了,然后将每个patch送入到encoder中。
抱歉,確實是有點混淆了。我的 patch + encoder 的意思是就是你說的「patchify是指直接将原始图像分patch,然后reshape + dense后就直接传入到transformer中」,這裡我的 encoder 就是 dense層。所以前面我才會問你如果「直接输入原始图像的Patch」要怎麼加上position embedding? 所以我的意思確實是「先patchify了,然后将每个patch送入到encoder中。」因為這裡我的encoder就是那一層dense。至於我後面說的encoder可以換成CNN,指的也是把那一層dense換成CNN。
那如果你指的encoder跟我指的不一樣,那我就不太清楚你的encoder是指甚麼了。是指「预训练的编码器」嗎?若是這樣那我大概懂了。只是你後面舉的例子「需要同时输入两幅图像I1,I2的时候」,因為前面的圖示是一個patch一個patch,我看太快,以為你的I1, I2 指的是patch。只是你舉的這個例子似乎不是很常見?因為既然是兩幅獨立的圖像,那很有可能本來就不相關的,又何來需要圖像間交互的問題呢?除非問題是比較兩張圖像的差異。但若只是相似度比較,或是指出這張圖有甚麼、那張圖沒有甚麼,預訓練的embedding 應該也很夠用了。我能想像到需要兩張圖片交互的一種可能情況是,需要兩張圖片做融合或條件式生成。若是如此,可能就會有你說的交互的問題了。
关于encoder的概念,可以去了解一下LDM(Latent Diffusion Model)。
两幅独立的图像,不代表不相关,比如“这两幅图片是否可以拼接起来?”,就需要比较两幅图像的连续性,这种任务原始图像反而好办,encoder之后的feature反而不好做。
1、GAN没有拟合概率密度,GAN只是直接生成样本,当然你可以说它背后的理论依据是拟合概率密度,但不管如何,它没法给出概率密度的计算公式(哪怕是隐式的);
2、单看patchify的话,它无非就是将原始图像输入到transformer中的一种比较自然的方式而已,没有太特殊的考虑;
3、我自己的实验中,位置编码是直接用2D-RoPE,直接加在Attention中的Q、K中,这一点类似 https://arxiv.org/abs/2402.12376
February 22nd, 2024
苏神,现实世界的图像分布在一个低维流形上(需要满足物理规律),如果encoder decoder足够大训练的足够好,那么信息损失是不是也没有那么大
理论上一个实数就足以编码无穷多图像,但事实很难训出这样的自编码器,所以还是看训练结果吧。
February 24th, 2024
三个想法:
一、无损压缩的要求太高了。用离散生成模型的bit per byte或者bit per pixel(bpp)来估计信息量,这相当于要求无损压缩24bpp的原始数据,要知道常用的YUV422-8b视频都才16bpp(这就已经相当于只有5.3 bit per byte了)
二、分辨率小的图每像素信息量更大,即使不考虑语义复杂性,单论Lipschitz也是高分辨率更小(颜色变化更平滑),
三、基于深度学习的图像有损压缩技术如https://arxiv.org/abs/2203.10886可以在0.1bpp的条件下实现高达30的PSNR,肉眼几乎看不出任何区别,而且这些技术为了能在100微秒内解码512乘768的图像,并没有追求最优的压缩率。
如以0.1bpp的信息量估计,16x的降采样也只要求25.6bit/token的信息量,也就是5000万的词表大小,如果采用MAGVIT-v2的token分解方法(也就是把一个token拆成两个),只需要两个7000大小的词表,完全可以接受。
1、当图像作为输入时,在不确定真实场景下会让你做什么任务的情况下,最保险的方式,就是直接输入原始图像,而不是经过各种预编码的特征;
2、既想要输入原始图像,又想要能够生成图像,那么我能想到的唯一组合方法就是patch-based diffusion,即本文的方案;
3、image tokenzier的压缩损失太多是肉眼可见的,连续型的encoder损失相对较小一些,但其实从输入大小来说,输入encoder的feature并不比输入原始RGB图像更省计算量,我想其他有损压缩技术也是如此;
4、目前的diffusion(LDM)或者多模态模态,基于encoder的feature作为图片输入的最实际原因,是因为这样训练会明显加快收敛速度,所以如果这个问题解决了,那么LDM这类做法就很有可能被淘汰了(至少在图像生成很可能被淘汰,视频应该不一定,毕竟视频相邻帧之间是高度冗余的)。
February 24th, 2024
苏神你好,上面你提到信息压缩的时候,对一张64*64的图片,假如使用4096的长度,需要的码本仅需要2^9=512的码本大小。最近出的Gemini pro和LWM,已经支持1M长度的上下文长度,理论上假设使用1024*1024的图像,按照上面的公式计算,且假设码本大小仍然为512,需要的上下文长度为1M。现在大多数多模态模型使用的尺寸为336/448,离散vqgan模型的码本大小也会超过512,这样算下来,是不是离散的方式仍然有自己的可行性呢。使用扩散模型的思路确实能提高生图的质量,但是如果要将一个多模态模型扩展模态到视频,音频,或者其他独特的模态,应该相应加入最适合这种模态的模态表征方式。这样直观给人的感觉,模型架构不够简洁统一,会让人觉得将图像视频理解模型和生成模型分开,会是更好的一种方式。
花上1M的context length才处理1024*1024的图像,我想大部分人都不能接受的。此外,你还要考虑生成,大概没有人能接受1M tokens的生成时间来生成一幅图像。此外,vocab_size的增加,几乎不会对context length造成本质的减少(vocab_size去到$512^2$,序列长度才减一半)。
看上去,文本和图像用不同的处理方式,确实显得不够优雅。但正如本文也提到了,文本是人类的创造,图像是大自然的记录,两者本就不是同一层次的东西,用不同的处理方式貌似也没有什么不合理的。人类创造的东西本质上就是低熵的(文明是一个熵减的过程),如果多模态模型只学人类创造的图像+文字,那么我相信离散化的方法大有可为,但很可惜我们需要学习大自然的图像(照片)。
February 27th, 2024
(2)式数据上式没有错。问题在于真正的图像相邻像素之间的关系是很大的。这一点何凯明的MAE理解的很深。图像就像是高维空间中的低维流形,空间本身的维度很大,但是流形本身的维度是很小的。所以这个公式只有理论上的意义。
正因为关系很大,所以已经从8比特降低了到3比特。