






11
Jun
SimBERTv2来了!融合检索和生成的RoFormer-Sim模型
By 苏剑林 | 2021-06-11 | 144016位读者 |去年我们放出了SimBERT模型,它算是我们开源的比较成功的模型之一,获得了不少读者的认可。简单来说,SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,这一功能是开创性的。
近段时间,我们以RoFormer为基础模型,对SimBERT相关技术进一步整合和优化,最终发布了升级版的RoFormer-Sim模型。
简介 #
RoFormer-Sim是SimBERT的升级版,我们也可以通俗地称之为“SimBERTv2”,而SimBERT则默认是指旧版。从外部看,除了基础架构换成了RoFormer外,RoFormer-Sim跟SimBERT没什么明显差别,事实上它们主要的区别在于训练的细节上,我们可以用两个公式进行对比:
\begin{array}{c}
\text{SimBERT} = \text{BERT} + \text{UniLM} + \text{对比学习} \\[5pt]
\text{RoFormer-Sim} = \text{RoFormer} + \text{UniLM} + \text{对比学习} + \text{BART} + \text{蒸馏}\\
\end{array}
除此之外,RoFormer-Sim用到了更多的训练数据,并且拓展到了一般句式,也就是说,不同于SimBERT仅仅局限于疑问句,RoFormer-Sim可以用来做一般句子的相似句生成,适用场景更大。其他训练细节还包括RoFormer-Sim用了更大的batch_size和maxlen等,这些在后面我们都会进一步介绍。
语料 #
SimBERT和RoFormer-Sim的关键之处,都是在于训练语料的构建。RoFormer-Sim的训练语料包括两部分:1、疑问类型相似句;2、通用类型相似句。对于疑问类相似句,我们还是像SimBERT一样,通过收集百度知道的相似问句,然后通过规则进一步清洗,这部分对我们来说已经很成熟了;对于通用类相似句,我们没有现成的地方可以搜集,于是我们提出了两种方案,一定程度上可以无监督地构建(伪)相似句对。
第一个方案是基于“同一个问题的答案是相似的”思想,假如我们有现成的问答语料,该语料对于同一个问题有多个答案,那么我们可以将每个答案分句,然后用一个现成的相似度函数来比较答案之间的相似度,挑出相似度超过某个阈值的句对作为相似句对使用;
第二个方案则是基于“同一篇章的句子是相似的”思想,它更加简单直接一点,就是将每个篇章分句,然后用一个现成的相似度函数两两计算相似度,挑出相似度超过某个阈值的句对作为相似句对使用,显然该方案的合理性更弱,所以它的阈值也更高。
这里涉及到一个“现成的相似度函数”,我们是直接使用Jaccard相似度的一个变体,换言之只需要一个规则的、字符级别的相似度就好了,语义上的关联,则通过篇章内部的关联以及预训练模型本身的泛化能力来获得。通过第一个方案,我们从几个阅读理解数据集中构建了约450万个(伪)相似句对;通过第二个方案,我们从30多G的平行预料中构建了约470万个(伪)相似句对;而爬取的问句则达到了约3000万个相似句组(一组可以构成多对)。从这个角度看来,问句的数目是远超于一般句式的,所以我们按照1:1的方式从中采样,使得每种句式的样本都均衡。
生成 #
RoFormer-Sim的训练方式跟SimBERT基本一样,如下图所示。稍微不同的是,为了增强模型的生成能力,在构造训练语料的时候,我们还随机地将输入句子的部分token替换为[MASK],这种预训练方法首先由BART提出。而我们跟BART的区别在于:BART是“输入带噪声的句子,输出原句子”,我们是“输入带噪声的句子,输出原句子的一个相似句”,理论上我们的任务还更难。
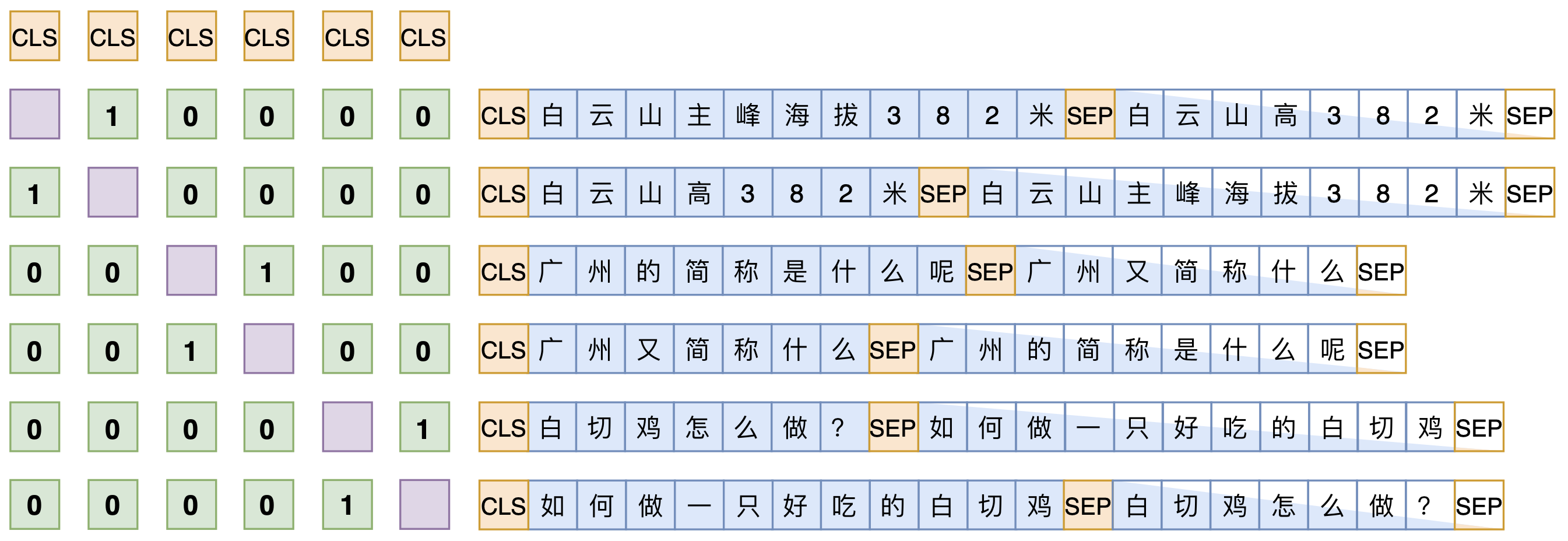
SimBERT训练方式示意图
生成效果没什么特别好的评测指标,我们直接目测一些例子就好:
gen_synonyms(u'广州和深圳哪个好?')
[
'深圳和广州哪个好?',
'广州和深圳哪个好',
'广州和深圳哪个更好?',
'深圳和广州哪个更好?',
'深圳和广州,那个更好?',
'深圳和广州哪个好一些呢?',
'深圳好还是广州好?',
'广州和深圳哪个地方好点?',
'广州好还是深圳好?',
'广州和深圳哪个好一点',
'广州和深圳哪个发展好?',
'深圳好还是广州好',
'深圳和广州哪个城市更好些',
'深圳比广州好吗?',
'到底深圳和广州哪个好?为什么呢?',
'深圳究竟好还是广州好',
'一般是深圳好还是广州好',
'广州和深圳那个发展好点',
'好一点的深圳和广州那边好?',
'深圳比广州好在哪里?'
]
gen_synonyms(u'科学技术是第一生产力。')
[
'科学技术是第一生产力!',
'科学技术是第一生产力',
'一、科学技术是第一生产力。',
'一是科学技术是第一生产力。',
'第一,科学技术是第一生产力。',
'第一生产力是科学技术。',
'因为科学技术是第一生产力。',
'科学技术是第一生产力知。',
'也即科学技术是第一生产力。',
'科学技术是第一生产力吗',
'科技是第一生产力。',
'因此,科学技术是第一生产力。',
'其次,科学技术是第一生产力。',
'科学技术才是第一生产力。',
'科学技术是第一生产力吗?',
'第二,科学技术是第一生产力。',
'所以说科学技术是第一生产力。',
'科学技术确实是第一生产力。',
'科学技术还是第一生产力',
'科学技术是第一生产力对吗?'
]总的来说,初步实现了任意句式的相似扩增,但问句的扩增效果优于一般句型,这是因为训练语料中问句的质量就明显高于一般句型。由于进行了仿BART式训练,所以除了直接进行相似句生成外,我们还可以自行把某些部分mask掉,让模型自行发散扩充,比如:
gen_synonyms(u'科学技术是第一生产力。', mask_idxs=[6, 7]) # mask掉“第一”
[
"科学技术是第一生产力",
"2、科学技术是第一生产力。",
"科学技术是第一生产力,也是第二生产力。",
"科学技术是第一生产力,科学发展是第二生产力。",
"9、科学技术是第一生产力。",
"第一,科学技术是一种生产力。",
"科学技术是生产力。",
"科学技术是第二生产力。",
"科学技术是第一生产力”现在提出来的。",
"一、科学技术是一种生产力。",
"科学技术是第一生产力是什么意思",
"科学技术是一种主要生产力。",
"一:科学技术是最高生产力。",
"指科学技术不是第一生产力。",
"科学技术是第二生产力,第一生产力又是第二生产力。",
"二、科学技术是一种生产力。",
"世界上第一种生产力是科学技术。",
"科学技术是社会主义生产力之一。",
"第二,科学技术也是第二生产力。",
"科技是一切生产力。"
]更多玩法,请大家自行挖掘了。
检索 #
增加一般句式的语料、引入仿BART式训练,这些改动都相对来说提升了生成模型的效果。然而,我们意外地发现,检索模型(即句子编码模型)的效果却降低了。估计的原因,可能是更多的语料、更大的噪声虽然加大了生成模型的难度,但对于对比学习来说,这些不同句式的或者带噪声的样本作为负样本,反而是难度降低了。比如,如果一个batch同时有疑问句和陈述句,那么模型可以简单地通过句式(而不是语义)就可以识别出不少负样本,从而降低了对语义的理解能力。
当然,SimBERT和RoFormer-Sim的本质定位都是相似句扩增模型,检索模型只是它的“副产品”,但我们仍然希望这个“副产品”能尽可能好一些。为此,我们在RoFormer-Sim训练完之后,进一步通过蒸馏的方式把SimBERT的检索效果转移到RoFormer-Sim上去,从而使得RoFormer-Sim的检索效果基本持平甚至优于SimBERT。蒸馏的方式很简单,假如对于同一批句子,SimBERT出来的句向量为$u_1, u_2, \cdots, u_n$,RoFormer-Sim出来的句向量为$v_1, v_2, \cdots,v_n$,那么就以
\begin{equation}\mathcal{L}_{\text{sim}} = \frac{\lambda}{n^2}\sum_{i=1}^n\sum_{j=1}^n (\cos(u_i,u_j)-\cos(v_i,v_j))^2\end{equation}
为loss进行学习,这里$\lambda=100$。当然,为了防止模型“遗忘”掉生成模型,蒸馏的同时还要加上生成损失,即$\mathcal{L}=\mathcal{L}_{\text{sim}}+\mathcal{L}_{\text{gen}}$。base版的蒸馏不需要很多步,大致5000步左右就可以训练完成了。
跟《无监督语义相似度哪家强?我们做了个比较全面的评测》一样,我们用同样的任务对比了SimBERT和RoFormer的检索效果(其中每一格的三个数据,分别代表“不加whitening”、“加whitening”、“加whitening-256”的效果,同之前的评测):
$$\small{\begin{array}{l|ccccc}
\hline
& \text{ATEC} & \text{BQ} & \text{LCQMC} & \text{PAWSX} & \text{STS-B} \\
\hline
\text{V1}\text{-P1} & 38.50 / \color{red}{23.64} / \color{red}{30.79} & 48.54 / \color{red}{31.78} / \color{red}{40.01} & 76.23 / \color{red}{75.05} / \color{red}{74.50} & 15.10 / \color{green}{18.49} / \color{green}{15.64} & 74.14 / \color{red}{73.37} / \color{green}{75.29} \\
\text{V1}\text{-P2} & 38.93 / \color{red}{27.06} / \color{red}{30.79} & 49.93 / \color{red}{35.38} / \color{red}{40.14} & 75.56 / \color{red}{73.45} / \color{red}{74.39} & 14.52 / \color{green}{18.51} / \color{green}{15.74} & 73.18 / \color{green}{73.43} / \color{green}{75.12} \\
\text{V1}\text{-P3} & 36.50 / \color{red}{31.32} / \color{red}{31.24} & 45.78 / \color{red}{29.17} / \color{red}{40.98} & 74.42 / \color{red}{73.79} / \color{red}{73.43} & 15.33 / \color{green}{18.39} / \color{green}{15.87} & 67.31 / \color{green}{70.70} / \color{green}{72.00} \\
\text{V1}\text{-P4} & 33.53 / \color{red}{29.04} / \color{red}{28.78} & 45.28 / \color{red}{34.70} / \color{red}{39.00} & 73.20 / \color{red}{71.22} / \color{red}{72.09} & 14.16 / \color{green}{17.32} / \color{green}{14.39} & 66.98 / \color{green}{70.55} / \color{green}{71.43} \\
\hline
\text{V2}\text{-P1} & 39.52 / \color{red}{25.31} / \color{red}{31.10} & 50.26 / \color{red}{33.47} / \color{red}{40.16} & 76.02 / \color{red}{74.92} / \color{red}{74.58} & 14.37 / \color{green}{19.31} / \color{green}{14.81} & 74.46 / \color{red}{71.00} / \color{green}{76.29} \\
\text{V2}\text{-P2} & 39.71 / \color{red}{32.60} / \color{red}{30.89} & 50.80 / \color{red}{37.62} / \color{red}{40.12} & 75.83 / \color{red}{73.45} / \color{red}{74.52} & 13.87 / \color{green}{19.50} / \color{green}{14.88} & 73.47 / \color{green}{74.56} / \color{green}{76.40} \\
\text{V2}\text{-P3} & 39.55 / \color{red}{24.61} / \color{red}{31.82} & 50.25 / \color{red}{29.59} / \color{red}{41.43} & 74.90 / \color{red}{73.95} / \color{red}{74.06} & 14.57 / \color{green}{18.85} / \color{green}{15.26} & 68.89 / \color{green}{71.40} / \color{green}{73.36} \\
\text{V2}\text{-P4} & 36.02 / \color{red}{29.71} / \color{red}{29.61} & 48.22 / \color{red}{35.02} / \color{red}{39.52} & 73.76 / \color{red}{71.19} / \color{red}{72.68} & 13.60 / \color{green}{16.67} / \color{green}{13.86} & 68.39 / \color{green}{71.04} / \color{green}{72.43} \\
\hline
\end{array}}$$
从表中可以看出,不管加不加whiteining,RoFormer-Sim在大部分任务上都超过了SimBERT,可见蒸馏之后的RoFormer-Sim的检索效果确实能获得提高,这个“副产品”也不至于太差了。
用同样的方法,我们也搞了个small版的RoFormer-Sim,这时候蒸馏用的是base版的RoFormer-Sim作为teacher模型,但蒸馏的步数需要比较多(50万左右),最终效果如下:
$$\small{\begin{array}{l|ccccc}
\hline
& \text{ATEC} & \text{BQ} & \text{LCQMC} & \text{PAWSX} & \text{STS-B} \\
\hline
\text{V1}_{\text{small}}\text{-P1} & 30.68 / \color{red}{27.56} / \color{red}{29.07} & 43.41 / \color{red}{30.89} / \color{red}{39.78} & 74.73 / \color{red}{73.21} / \color{red}{73.50} & 15.89 / \color{green}{17.96} / \color{green}{16.75} & 70.54 / \color{green}{71.39} / \color{green}{72.14} \\
\text{V1}_{\text{small}}\text{-P2} & 31.00 / \color{red}{29.14} / \color{red}{29.11} & 43.76 / \color{red}{36.86} / \color{red}{39.84} & 74.21 / \color{red}{73.14} / \color{red}{73.67} & 16.17 / \color{green}{18.12} / \color{green}{16.81} & 70.10 / \color{green}{71.40} / \color{green}{72.28} \\
\text{V1}_{\text{small}}\text{-P3} & 30.03 / \color{red}{21.24} / \color{red}{29.30} & 43.72 / \color{red}{31.69} / \color{red}{40.81} & 72.12 / \color{red}{70.27} / \color{red}{70.52} & 16.93 / \color{green}{21.68} / \color{green}{18.75} & 66.55 / \color{red}{66.11} / \color{green}{69.19} \\
\text{V1}_{\text{small}}\text{-P4} & 29.52 / \color{red}{28.41} / \color{red}{28.57} & 43.52 / \color{red}{36.56} / \color{red}{40.49} & 70.33 / \color{red}{68.75} / \color{red}{69.01} & 15.39 / \color{green}{21.57} / \color{green}{16.34} & 64.73 / \color{green}{68.12} / \color{green}{68.24} \\
\hline
\text{V2}_{\text{small}}\text{-P1} & 37.33 / \color{red}{23.59} / \color{red}{31.31} & 47.90 / \color{red}{29.21} / \color{red}{42.07} & 74.72 / \color{green}{74.94} / \color{red}{74.69} & 13.41 / \color{green}{15.30} / \color{green}{13.61} & 71.48 / \color{red}{69.01} / \color{green}{75.10} \\
\text{V2}_{\text{small}}\text{-P2} & 37.42 / \color{red}{31.25} / \color{red}{31.18} & 49.15 / \color{red}{38.01} / \color{red}{41.98} & 75.21 / \color{red}{73.47} / \color{red}{74.78} & 13.38 / \color{green}{15.87} / \color{green}{13.69} & 72.06 / \color{green}{73.92} / \color{green}{75.69} \\
\text{V2}_{\text{small}}\text{-P3} & 36.71 / \color{red}{30.33} / \color{red}{31.25} & 49.73 / \color{red}{31.03} / \color{red}{42.74} & 74.25 / \color{red}{72.72} / \color{red}{74.19} & 14.58 / \color{green}{18.68} / \color{red}{14.40} & 69.12 / \color{green}{71.07} / \color{green}{72.68} \\
\text{V2}_{\text{small}}\text{-P4} & 32.80 / \color{red}{27.87} / \color{red}{29.65} & 46.80 / \color{red}{36.93} / \color{red}{41.31} & 72.30 / \color{red}{69.94} / \color{green}{72.38} & 13.45 / \color{green}{16.93} / \color{red}{13.38} & 67.21 / \color{green}{70.42} / \color{green}{71.39} \\
\hline
\end{array}}$$
总结 #
本文介绍和发布了我们SimBERT的升级版——RoFormer-Sim(SimBERTv2),它既可以用来扩充相似句子,也是语义相似度问题的一个较高的baseline。相比SimBERT,它最大的特点是将句型拓展到了一般类型,不再局限于相似问句。更多的玩法欢迎读者进一步挖掘和分享~
转载到请包括本文地址:https://www.kexue.fm/archives/8454
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 11, 2021). 《SimBERTv2来了!融合检索和生成的RoFormer-Sim模型 》[Blog post]. Retrieved from https://www.kexue.fm/archives/8454
@online{kexuefm-8454,
title={SimBERTv2来了!融合检索和生成的RoFormer-Sim模型},
author={苏剑林},
year={2021},
month={Jun},
url={\url{https://www.kexue.fm/archives/8454}},
}

June 18th, 2021
苏神如果想改善检索效果,1,在自己语料上集训练(我们有一些 相似语料,不都是问句),是基于 simbert好还是 simbertv2好呢;2,若果用simbert,直接按官方的 https://github.com/ZhuiyiTechnology/simbert/blob/master/simbert.py 加载 simbert继续train就可以吧 需要注意啥嘛,感谢苏神
1、随你,推荐v2;
2、没想到有什么要特别注意的。
再训练我们只用stage1.py 就可以吧
是
June 20th, 2021
请问苏神,代码中用到的语料的格式或者下载链接有吗?谢谢
f1 = read('/root/data_pretrain/synonyms_shuf.json')
f2 = read('/root/data_pretrain/synonym_answers_shuf.json')
f3 = read('/root/data_pretrain/synonym/synonym_gen_2_shuf.json')
https://github.com/ZhuiyiTechnology/simbert/issues/2
第一个的格式搜索到了。
这是自己要准备的语料,跟 https://github.com/ZhuiyiTechnology/simbert/blob/master/data_sample.json 格式一致。
后两个的,请问是一样的格式?
没有指定格式。自行读懂代码,然后改写generator来匹配自己的语料格式。
June 20th, 2021
另外请问下苏神,task_question_answer_generation_by_seq2seq.py
这里的做《问答对自动构建》所需要的语料WebQA.json和SougouQA.json那里可以下载呢?第一个我下载了发现格式报错,第二个全网找不到下载的地方。
谢谢!
https://github.com/bojone/dgcnn_for_reading_comprehension
June 22nd, 2021
谢谢!
June 24th, 2021
求数据
July 16th, 2021
你好,请问苏神,tensorflow支持2.0以上版本吗?
刚试了用tensorflow2.2.0也可以。
August 9th, 2021
roformer-sim模型,输入token_ids sequence_padding的长度不一样,得到的句向量不同,对应得到的文本相似度差异也较大。请问下是有这个问题吗?还是我这边使用的有问题?
我没发现这个问题。
感谢赐教。做了多次验证,roformer-sim在没有gpu的机器上padding 64以下均会有差异,64及以上句向量基本一致。在有gpu的机器上没有这个问题,恒一致。 sim-bert都没有这个问题。使用上应该没啥问题了,虽然不知道为啥,哈哈。
还有这回事,我还真不知道~基本没用过cpu测。
September 23rd, 2021
大佬,stage1代码loss中的compute_loss_of_similarity方法,return loss是不是应该换成return K.mean(loss)
最终结果等价的。要是有强迫症可以加上~
October 29th, 2021
苏神啥时候训练一个中文版的simCSE,我们想做基于语义的文档检索功能,因为文档太大仅用一条向量很难表征。因此我们想抽取或者生成一些信息密度大的关键语句表征文档,语义搜索时让query与这些关键语句进行相似度比较。这几年的相似度比较打算用simCSE,但遗憾的是没有中文版。苏神你也评论过那篇论文,整个中文版的对你来说是小菜一碟吧。
如果你说的是无监督的中文版SimCSE,那么这里就测过 https://kexue.fm/archives/8348 ,直接使用的效果是不如SimBERT和RoFormer-Sim的。
November 16th, 2021
苏神,你好,我用stage2的代码训练模型出现下面的错误,是什么原因呢,自己看了一直没找到原因
Traceback (most recent call last):
File "/home/yan/Projects/reformer-sim/train/stage2.py", line 129, in
return_keras_model=False,
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/bert4keras/models.py", line 2444, in build_transformer_model
transformer.load_weights_from_checkpoint(checkpoint_path)
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/bert4keras/models.py", line 298, in load_weights_from_checkpoint
raise e
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/bert4keras/models.py", line 292, in load_weights_from_checkpoint
values.append(self.load_variable(checkpoint, v))
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/bert4keras/models.py", line 692, in load_variable
variable = super(BERT, self).load_variable(checkpoint, name)
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/bert4keras/models.py", line 263, in load_variable
return tf.train.load_variable(checkpoint, name)
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/tensorflow/python/training/checkpoint_utils.py", line 84, in load_variable
return reader.get_tensor(name)
File "/home/yan/anaconda3/envs/reformer-sim/lib/python3.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 678, in get_tensor
return CheckpointReader_GetTensor(self, compat.as_bytes(tensor_str))
tensorflow.python.framework.errors_impl.NotFoundError: Key bert/embeddings/position_embeddings not found in checkpoint
第一阶段保存的权重,是不能直接用build_transformer_model加载的,这只需要看看build_transformer_model的源码就知道了,它是用load_weights_from_checkpoint加载的,所以需要把权重用save_weights_as_checkpoint进行转换。这在bert4keras的GitHub已经提过多次。