






26
Oct
浅谈神经网络中激活函数的设计
By 苏剑林 | 2017-10-26 | 61045位读者 |激活函数是神经网络中非线性的来源,因为如果去掉这些函数,那么整个网络就只剩下线性运算,线性运算的复合还是线性运算的,最终的效果只相当于单层的线性模型。
那么,常见的激活函数有哪些呢?或者说,激活函数的选择有哪些指导原则呢?是不是任意的非线性函数都可以做激活函数呢?
这里探究的激活函数是中间层的激活函数,而不是输出的激活函数。最后的输出一般会有特定的激活函数,不能随意改变,比如二分类一般用sigmoid函数激活,多分类一般用softmax激活,等等;相比之下,中间层的激活函数选择余地更大一些。
浮点误差都行! #
理论上来说,只要是非线性函数,都有做激活函数的可能性,一个很有说服力的例子是,最近OpenAI成功地利用了浮点误差来做激活函数,其中的细节,请阅读OpenAI的博客:
https://blog.openai.com/nonlinear-computation-in-linear-networks/
或者阅读机器之心的介绍:
https://mp.weixin.qq.com/s/PBRzS4Ol_Zst35XKrEpxdw
尽管如此,不同的激活函数其训练成本是不同的,虽然OpenAI的探索表明连浮点误差都可以做激活函数,但是由于这个操作的不可微分性,因此他们使用了“进化策略”来训练模型,所谓“进化策略”,是诸如遗传算法之类的耗时耗力的算法。
Relu开创的先河 #
那加上可微性,使得可以用梯度下降来训练,是不是就没问题了呢?其实也不尽然,神经网络发明之初,一般使用的是Sigmoid函数作为激活函数
$$\begin{equation}\text{sigmoid}(x)=\sigma(x)=\frac{1}{1+e^{-x}}\end{equation}$$
这个函数的特点就是左端趋近于0,右端趋近于1,两端都趋于饱和,如下图
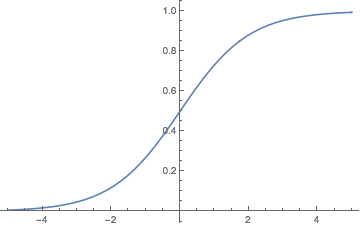
sigmoid
而因为这样,它在两端的导数都趋于0,而因为我们是用梯度下降优化的,导数趋于零,使得每次更新的量都很少(正比于梯度),所以更新起来比较困难。尤其是层数多了之后,由于求导的链式法则,那么每次更新的量就正比于梯度的$n$次方,优化就更加困难了,因此刚开始的神经网络都做不深。
一个标志性的激活函数就是ReLu函数,它的定义很简单:
$$\begin{equation}\text{relu}(x)=\max(x,0)\end{equation}$$
其图像是
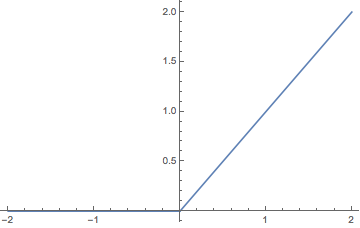
relu
这是个分段线性函数,显然其导数在正半轴为1,负半轴为0,这样它在整个实数域上有一半的空间是不饱和的。相比之下,sigmoid函数几乎全部区域都是饱和的(饱和区间占比趋于1,饱和的定义是导数很接近0)。
ReLu是分段线性函数,它的非线性性很弱,因此网络一般要做得很深。但这正好迎合了我们的需求,因为在同样效果的前提下,往往深度比宽度更重要,更深的模型泛化能力更好。所以自从有了Relu激活函数,各种很深的模型都被提出来了,一个标志性的事件是应该是VGG模型和它在ImageNet上取得的成功,至于后来的发展就不详细说了。
更好的Swish #
尽管ReLu的战绩很辉煌,但也有人觉得ReLu函数还有一半区域饱和是一个很大的不足,因此提出了相关的变种,如LeakyReLU、PReLU等,这些改动都大同小异。
前几天,Google大脑团队提出了一个新的激活函数,叫Swish,其消息可以参考
http://mp.weixin.qq.com/s/JticD0itOWH7Aq7ye1yzvg
其定义为
$$\begin{equation}\text{swish}(x)=x\cdot\sigma(x)=\frac{x}{1+e^{-x}}\end{equation}$$
其图像如下
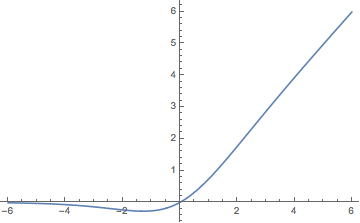
Swish
团队的测试结果表明该函数在很多模型都优于ReLu。
从图像上来看,Swish函数跟ReLu差不多,唯一区别较大的是接近于0的负半轴区域。马后炮说一句,其实这个激活函数就连笔者也思考过,因为这跟facebook提出的GLU激活函数是类似的,GLU激活函数为
$$\begin{equation}(\boldsymbol{W}_1\boldsymbol{x}+\boldsymbol{b}_1)\otimes \sigma(\boldsymbol{W}_2\boldsymbol{x}+\boldsymbol{b}_2)\end{equation}$$
也就是说,分别训练两组参数,其中一组用sigmoid激活,然后乘上另一组,这里的$\sigma(\boldsymbol{W}_2\boldsymbol{x}+\boldsymbol{b}_2)$就称为“门”,也就是GLU中的G的意思(gate)。而Swish函数则相当于两组参数都取同样的,只训练一组参数。
改进思路 #
Swish函数惹来了一些争议,有些人认为Google大脑小题大作了,简单改进一个激活函数,小团队就可以玩了,Google大脑这些大团队应该往更高端的方向去做。但不过怎样,Google大脑做了很多实验,结果都表明Swish优于ReLu。那么我们就需要思考一下,背后的原因是什么呢?
下面的分析纯属博主的主观臆测,目前没有理论或实验上的证明,请读者斟酌阅读。我觉得,Swish优于ReLu的一个很重要的原因是跟初始化有关。
Swish在原点附近不是饱和的,只有负半轴远离原点区域才是饱和的,而ReLu在原点附近也有一半的空间是饱和的。而我们在训练模型时,一般采用的初始化参数是均匀初始化或者正态分布初始化,不管是哪种初始化,其均值一般都是0,也就是说,初始化的参数有一半处于ReLu的饱和区域,这使得刚开始时就有一半的参数没有利用上。特别是由于诸如BN之类的策略,输出都自动近似满足均值为0的正态分布,因此这些情况都有一半的参数位于ReLu的饱和区。相比之下,Swish好一点,因为它在负半轴也有一定的不饱和区,所以参数的利用率更大。
前面说到,就连笔者都曾思考过Swish激活函数,但没有深入研究,原因之一是它不够简洁漂亮,甚至我觉得它有点丑~~看到Swish的实验结果那么好,我想有没有类似的、更加好看的激活函数呢?我想到了一个
$$\begin{equation}x\cdot\min(1,e^x)\end{equation}$$
它的图像是
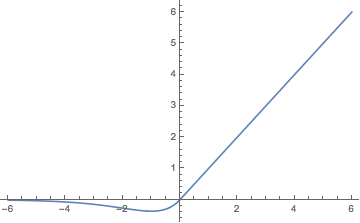
我自己构思的激活函数
其实样子跟Swish差不多,思路大概是正半轴维持$x$,负半轴想一个先降后升还趋于0的函数,我想到了$xe^{-x}$,稍微调整就得到了这个函数了。在我的一些模型中,它的效果甚至比Swish要好些(在我的问答模型上)。当然我只做了一点实验,就不可能有那么多精力和算力去做对比实验了。
与Swish的比较,橙色是Swish。
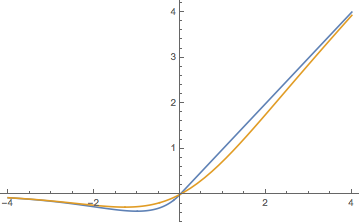
与Swish(橙色)的比较
要提醒的是,如果要用这个函数,不能直接用这个形式写,因为$e^x$的计算可能溢出,一种不会溢出的写法是
$$\begin{equation}\max(x, x\cdot e^{-|x|})\end{equation}$$
或者用ReLu函数写成
$$\begin{equation}x + \text{relu}(x\cdot e^{-|x|}-x)\end{equation}$$
难道好用的激活函数都像我们作业上的勾(√)?
转载到请包括本文地址:https://www.kexue.fm/archives/4647
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Oct. 26, 2017). 《浅谈神经网络中激活函数的设计 》[Blog post]. Retrieved from https://www.kexue.fm/archives/4647
@online{kexuefm-4647,
title={浅谈神经网络中激活函数的设计},
author={苏剑林},
year={2017},
month={Oct},
url={\url{https://www.kexue.fm/archives/4647}},
}

September 4th, 2018
那可以給這個激活函數取個名字嗎?
August 5th, 2019
博主用什么软件画的图啊
如果是说本文的图的话,那是用mathematica画的~
June 20th, 2024
苏神您好!想请教一下:如果ReLU结合BN的话,每层零均值(BN)然后再去掉一半激活(ReLU),那到最后一层得到的值岂不是就非常稀疏了,这样深层网络岂不是很难更新?如果这个说法是对的,那使用残差后者RMSNorm是否也是可以缓解这个问题?
从概率上来讲,就是每一层都保持一半为0,而不是第一层一半为0、第二层3/4为0、第三层7/8都为0,所以按道理问题不大。