






2
May
基于Conv1D的光谱分类模型(一维序列分类)
By 苏剑林 | 2018-05-02 | 155594位读者 |前段时间天池出了个天文数据挖掘竞赛——LAMOST光谱分类(将对应的光谱识别为4类中的一类),虽然没有奖金,但还是觉得挺有意思,所以就报名参加了。做了一段时间,成绩自我感觉还可以,然而最后我却忘记了(或者说根本就没留意到)初赛最后两天还有一步是提交新的测试集结果,然后就没有然后了,留下了一个未竟的模型,可谓“出师未捷身先死”,还是被自己弄死的~

天文数据挖掘大赛——天体光谱智能分类
后来跟其他参赛选手讨论了一下,发现其实我的这个模型还是不错的。当时我记得初赛第一名的成绩是0.83+,而我当时的成绩是0.82+,排名大概是第4、5左右,而且据说很多分数在0.8+的队伍都已经使用了融合模型,而我这0.82+的成绩仅仅是单模型的结果~在平时的群聊中发现也有不少朋友在做一维序列分类模型,而光谱分类本质上也就是一个一维的序列分类,所以分享一下模型,估计对相关朋友会有一定的参考价值。
模型 #
事实上也不是什么特别的模型,就是普通的一维卷积加残差,对于熟悉图像处理的朋友,这实在是再普通不过的结构了。
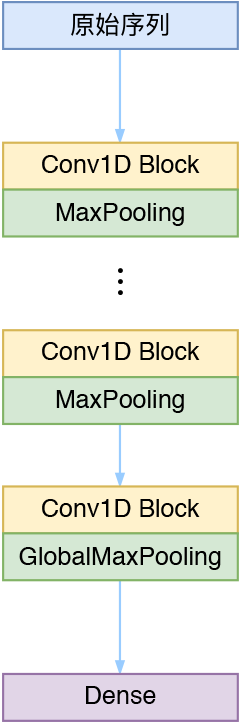
光谱识别的CNN模型
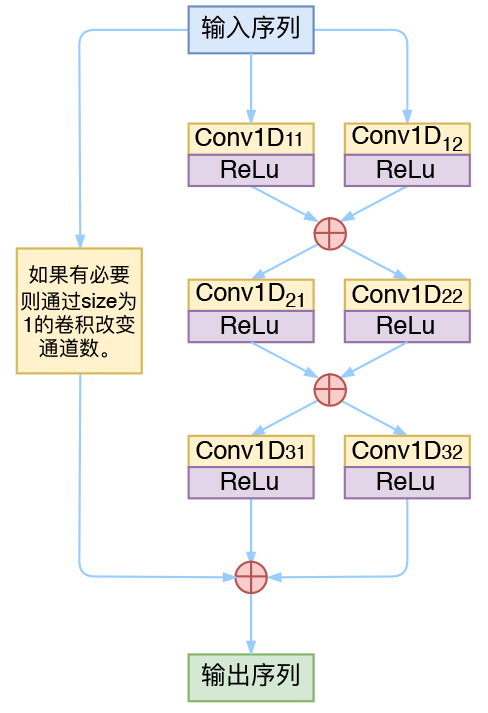
光谱CNN的Block结构图
其中每个Conv1D Block的形式如右图,具体参数请看下面的代码即可。
原理 #
在这里顺便说一下为什么可以用CNN来做。
适用于CNN的特征应该要满足局部相关性,也就是特征之间的关联主要体现在局部上,并且由局部延伸到整体,显然图像、音频都是满足这个特性的,所以目前主流的图像和音频识别模型都用CNN来做。
而对于光谱序列,其实相当于一个函数图像(2600个点),如下图。它也是局部相关性的,所以我们用CNN来解决,当然用LSTM等RNN模型也并非不可以,但是RNN无法并行,对于这样的长序列是难以忍受的。而为了使用一维卷积,我们需要将序列转化为$2600\times 1$的格式。此外,我们了解到人眼识别光谱是靠识别发射线和吸收线的,简单来看这就是差分比较大的特征,而为了识别出这类特征,我们所有的池化都是用最大池化,并且激活函数也只用relu[因为relu(x)=max(x,0)。]。
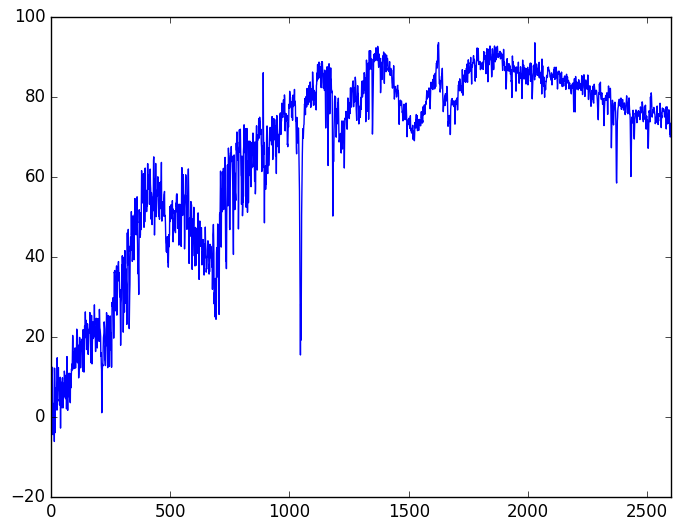
光谱参考例子
此外,由于这种序列到比较长(长达2600维),因此采用了一些trick:用到了膨胀卷积,并且Block数尽可能多,每一个Block后面都加一个池化来降维。
训练 #
在给出训练代码之前,先讲一下训练过程。
大赛的评测指标是marco f1 score,也就是每一类都算出一个F1,然后将4类的f1值平均。一般来说,F1值都是不可导的,所以marco f1 score也不可导,无法直接用来做loss。但是我们可以写出marco f1 score(的相反数)的近似公式:
def score_loss(y_true, y_pred):
loss = 0
for i in np.eye(4):
y_true_ = K.constant([list(i)]) * y_true
y_pred_ = K.constant([list(i)]) * y_pred
loss += 0.5 * K.sum(y_true_ * y_pred_) / K.sum(y_true_ + y_pred_ + K.epsilon())
return - K.log(loss + K.epsilon())其中y_true是目标的one hot分布,而y_pred则是预测的每一类的概率。咋看之下可能不好理解,读者需要理解F1的计算公式,然后将F1的计算公式表达为one hot输入的计算格式,才能逐步理解它。
为了达到这个评测指标最优,我先用adam优化器(学习率为0.001)和普通的分类交叉熵将模型训练到最优,然后改用score_loss并将学习率降低为0.0001继续训练模型到最优。这些过程在代码中都有体现。直接用marco f1 score作为loss训练却不会收敛,这是一件比较奇怪的事情~
代码 #
下面是参考代码,确实没有什么特别的。如果有问题,欢迎留言讨论。
#! -*- coding: utf-8 -*-
import numpy as np
import os,glob
import pandas as pd
import json
import keras.backend as K
from keras.callbacks import Callback
from keras.utils import to_categorical
from tqdm import tqdm
np.random.seed(2018)
# 数据读取。
# 光谱的存储方式为一个txt存一个样本,txt里边是字符串格式的序列
# 对于做其他序列分类的读者,只需要知道这里就是生成序列的样本就就行了
class Data_Reader:
def __init__(self):
self.labels = pd.read_csv('../first_train_index_20180131.csv')
self.label2id = {'star':0, 'unknown':1, 'galaxy':2, 'qso':3}
self.id2label = ['star', 'unknown', 'galaxy', 'qso']
self.labels['type'] = self.labels['type'].apply(lambda s: self.label2id[s])
self.labels = dict(zip(self.labels['id'], self.labels['type']))
if os.path.exists('../train_data.json'): # 读取保存好的数据
print 'Found. Reading ...'
self.train_data = json.load(open('../train_data.json'))
self.valid_data = json.load(open('../valid_data.json'))
self.nb_train = len(self.train_data)
self.nb_valid = len(self.valid_data)
else: # 如果还没有保存好,则直接从原始数据构建
print 'Not Found. Preparing ...'
self.data = glob.glob('../train/*.txt')
np.random.shuffle(self.data)
self.train_frac = 0.8
self.nb_train = int(self.train_frac*len(self.data))
self.nb_valid = len(self.data) - self.nb_train
self.train_data = self.data[:self.nb_train]
self.valid_data = self.data[self.nb_train:]
json.dump(self.train_data, open('../train_data.json', 'w'))
json.dump(self.valid_data, open('../valid_data.json', 'w'))
self.input_dim = len(self.read_one(self.train_data[0]))
self.fracs = [0.8, 0.1, 0.05, 0.05] # 每个batch中,每一类的采样比例
self.batch_size = 160 # batch_size
for i in range(4):
self.fracs[i] = int(self.fracs[i]*self.batch_size)
self.fracs[0] = self.batch_size - np.sum(self.fracs[1:])
def read_one(self, fn):
return np.array(json.loads('[' + open(fn).read() + ']'))
def for_train(self): # 生成训练集
train_data = [[], [], [], []]
for n in self.train_data:
train_data[self.labels[int(n.split('/')[2].split('.')[0])]].append(n)
print 'Samples:',self.fracs
Y = np.array([0]*self.fracs[0] + [1]*self.fracs[1] + [2]*self.fracs[2] + [3]*self.fracs[3])
Y = to_categorical(np.array(Y), 4)
while True:
X = []
for i in range(4):
for n in np.random.choice(train_data[i], self.fracs[i]):
X.append(self.read_one(n))
X = np.expand_dims(np.array(X), 2)/100.
yield X,Y
X = []
def for_valid(self): # 生成验证集
X,Y = [],[]
for n in self.valid_data:
X.append(self.read_one(n))
Y.append(self.labels[int(n.split('/')[2].split('.')[0])])
if len(X) == self.batch_size or n == self.valid_data[-1]:
X = np.expand_dims(np.array(X), 2)/100.
Y = to_categorical(np.array(Y), 4)
yield X,Y
X,Y = [],[]
D = Data_Reader()
from keras.layers import *
from keras.models import Model
import keras.backend as K
def BLOCK(seq, filters): # 定义网络的Block
cnn = Conv1D(filters*2, 3, padding='SAME', dilation_rate=1, activation='relu')(seq)
cnn = Lambda(lambda x: x[:,:,:filters] + x[:,:,filters:])(cnn)
cnn = Conv1D(filters*2, 3, padding='SAME', dilation_rate=2, activation='relu')(cnn)
cnn = Lambda(lambda x: x[:,:,:filters] + x[:,:,filters:])(cnn)
cnn = Conv1D(filters*2, 3, padding='SAME', dilation_rate=4, activation='relu')(cnn)
cnn = Lambda(lambda x: x[:,:,:filters] + x[:,:,filters:])(cnn)
if int(seq.shape[-1]) != filters:
seq = Conv1D(filters, 1, padding='SAME')(seq)
seq = add([seq, cnn])
return seq
#搭建模型,就是常规的CNN加残差加池化
input_tensor = Input(shape=(D.input_dim, 1))
seq = input_tensor
seq = BLOCK(seq, 16)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 16)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 32)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 32)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 64)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 64)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 128)
seq = MaxPooling1D(2)(seq)
seq = BLOCK(seq, 128)
seq = Dropout(0.5, (D.batch_size, int(seq.shape[1]), 1))(seq)
seq = GlobalMaxPooling1D()(seq)
seq = Dense(128, activation='relu')(seq)
output_tensor = Dense(4, activation='softmax')(seq)
model = Model(inputs=[input_tensor], outputs=[output_tensor])
model.summary()
# 定义marco f1 score的相反数作为loss
def score_loss(y_true, y_pred):
loss = 0
for i in np.eye(4):
y_true_ = K.constant([list(i)]) * y_true
y_pred_ = K.constant([list(i)]) * y_pred
loss += 0.5 * K.sum(y_true_ * y_pred_) / K.sum(y_true_ + y_pred_ + K.epsilon())
return - K.log(loss + K.epsilon())
# 定义marco f1 score的计算公式
def score_metric(y_true, y_pred):
y_true = K.argmax(y_true)
y_pred = K.argmax(y_pred)
score = 0.
for i in range(4):
y_true_ = K.cast(K.equal(y_true, i), 'float32')
y_pred_ = K.cast(K.equal(y_pred, i), 'float32')
score += 0.5 * K.sum(y_true_ * y_pred_) / K.sum(y_true_ + y_pred_ + K.epsilon())
return score
from keras.optimizers import Adam
model.compile(loss='categorical_crossentropy', # 交叉熵作为loss
optimizer=Adam(1e-3),
metrics=[score_metric])
try:
model.load_weights('guangpu_highest.model')
except:
pass
def predict():
import time
data = pd.read_csv('../first_test_index_20180131.csv')['id']
data = '../test/' + data.apply(str) + '.txt'
data = list(data)
I,X,Y = [],[],[]
for n in tqdm(iter(data)):
X.append(D.read_one(n))
I.append(int(n.split('/')[2].split('.')[0]))
if len(X) == D.batch_size:
X = np.expand_dims(np.array(X), 2)/100.
y = model.predict(X)
y = y.argmax(axis=1)
Y.extend(list(y))
X = []
d = pd.DataFrame(list(zip(I, Y)))
d.columns = ['id', 'type']
d['type'] = d['type'].apply(lambda s: D.id2label[s])
d.to_csv('result_%s.csv'%(int(time.time())), index=None, header=None)
if __name__ == '__main__':
# 定义Callback器,计算验证集的score,并保存最优模型
class Evaluate(Callback):
def __init__(self):
self.scores = []
self.highest = 0.
def on_epoch_end(self, epoch, logs=None):
R,T = [],[]
for x,y in D.for_valid():
y_ = model.predict(x)
R.extend(list(y.argmax(axis=1)))
T.extend(list(y_.argmax(axis=1)))
R,T = np.array(R),np.array(T)
score = 0
for i in range(4):
R_ = (R == i)
T_ = (T == i)
score += 0.5 * (R_ * T_).sum() / (R_.sum() + T_.sum() + K.epsilon())
self.scores.append(score)
if score >= self.highest: # 保存最优模型权重
self.highest = score
model.save_weights('guangpu_highest.model')
json.dump([self.scores, self.highest], open('valid.log', 'w'))
print ' score: %f%%, highest: %f%%'%(score*100, self.highest*100)
evaluator = Evaluate()
# 第一阶段训练
history = model.fit_generator(D.for_train(),
steps_per_epoch=500,
epochs=50,
callbacks=[evaluator])
model.compile(loss=score_loss, # 换一个loss
optimizer=Adam(1e-4),
metrics=[score_metric])
try:
model.load_weights('guangpu_highest.model')
except:
pass
# 第二阶段训练
history = model.fit_generator(D.for_train(),
steps_per_epoch=500,
epochs=50,
callbacks=[evaluator])转载到请包括本文地址:https://www.kexue.fm/archives/5505
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 02, 2018). 《基于Conv1D的光谱分类模型(一维序列分类) 》[Blog post]. Retrieved from https://www.kexue.fm/archives/5505
@online{kexuefm-5505,
title={基于Conv1D的光谱分类模型(一维序列分类)},
author={苏剑林},
year={2018},
month={May},
url={\url{https://www.kexue.fm/archives/5505}},
}

February 13th, 2019
输入(None, inputdim, 1),经过卷积改变了第三个维度值,经过池化改变了第二个维度值。想请教一下,一维卷积怎么样能够同时改变第二和三个维度值。因为想用conv代替Dense,
GlobalMaxPooling1D()和Flatten()在这种场景下,哪个处理好点
Conv1D和AveragePooling1D/MaxPooling1D混用。
April 2nd, 2019
lambda x: x[:,:,:filters] + x[:,:,filters:],这里的应不应该把张量cat起来,而不是相加?
相加维度就减少一半了,丢失了很多信息
大哥,先把文章看完然后搞明白逻辑好不?如果x[:,:,:filters]和x[:,:,filters:]拼起来,那不就是x了吗,还多此一举干嘛...
前面的“光谱CNN的Block结构图”已经说了,要搞信息的多通道传输,代码就是按照讲解写的,你的问题的答案都在本文里。
April 3rd, 2019
你的代码做一次卷积后,你把结果切成了一半产生了两个通道,相加又成了一个通道。
是不是应该把卷积后划分的两个通道分别卷积后,再相加。像你画的网络那样。
图上的意思是:将同一个输入,做两个不同的卷积,然后将结果相加。
然后,做两个不同的卷积,跟做一个两倍通道数的卷积,然后对半划分,是完全等效的~
December 24th, 2019
请问有没有对keras的一维卷积进行mask的做法呢,谢谢苏神
参考:https://kexue.fm/archives/6810