






28
Dec
Transformer升级之路:6、旋转位置编码的完备性分析
By 苏剑林 | 2022-12-28 | 25587位读者 | 引用在去年的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE),当时的出发点只是觉得用绝对位置来实现相对位置是一件“很好玩的事情”,并没料到其实际效果还相当不错,并为大家所接受,不得不说这真是一个意外之喜。后来,在《Transformer升级之路:4、二维位置的旋转式位置编码》中,笔者讨论了二维形式的RoPE,并研究了用矩阵指数表示的RoPE的一般解。
既然有了一般解,那么自然就会引出一个问题:我们常用的RoPE,只是一个以二维旋转矩阵为基本单元的分块对角矩阵,如果换成一般解,理论上效果会不会更好呢?本文就来回答这个问题。
指数通解
在《Transformer升级之路:4、二维位置的旋转式位置编码》中,我们将RoPE抽象地定义为任意满足下式的方阵
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\label{eq:re}\end{equation}
2
Nov
利用CUR分解加速交互式相似度模型的检索
By 苏剑林 | 2022-11-02 | 18602位读者 | 引用文本相似度有“交互式”和“特征式”两种做法,想必很多读者对此已经不陌生,之前笔者也写过一篇文章《CoSENT(二):特征式匹配与交互式匹配有多大差距?》来对比两者的效果。总的来说,交互式相似度效果通常会好些,但直接用它来做大规模检索是不现实的,而特征式相似度则有着更快的检索速度,以及稍逊一筹的效果。
因此,如何在保证交互式相似度效果的前提下提高它的检索速度,是学术界一直都有在研究的课题。近日,论文《Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization》提出了一份新的答卷:CUR分解。

CUR分解示意图
9
Aug
线性Transformer应该不是你要等的那个模型
By 苏剑林 | 2021-08-09 | 76040位读者 | 引用在本博客中,我们已经多次讨论过线性Attention的相关内容。介绍线性Attention的逻辑大体上都是:标准Attention具有$\mathscr{O}(n^2)$的平方复杂度,是其主要的“硬伤”之一,于是我们$\mathscr{O}(n)$复杂度的改进模型,也就是线性Attention。有些读者看到线性Attention的介绍后,就一直很期待我们发布基于线性Attention的预训练模型,以缓解他们被BERT的算力消耗所折腾的“死去活来”之苦。
然而,本文要说的是:抱有这种念头的读者可能要失望了,标准Attention到线性Attention的转换应该远远达不到你的预期,而BERT那么慢的原因也并不是因为标准Attention的平方复杂度。
BERT之反思
按照直观理解,平方复杂度换成线性复杂度不应该要“突飞猛进”才对嘛?怎么反而“远远达不到预期”?出现这个疑惑的主要原因,是我们一直以来都没有仔细评估一下常规的Transformer模型(如BERT)的整体计算量。
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 73345位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
5
Jun
从一个单位向量变换到另一个单位向量的正交矩阵
By 苏剑林 | 2021-06-05 | 32753位读者 | 引用这篇文章我们来讨论一个比较实用的线性代数问题:
给定两个$d$维单位(列)向量$\boldsymbol{a},\boldsymbol{b}$,求一个正交矩阵$\boldsymbol{T}$,使得$\boldsymbol{b}=\boldsymbol{T}\boldsymbol{a}$。
由于两个向量模长相同,所以很显然这样的正交矩阵必然存在,那么,我们怎么把它找出来呢?
二维
不难想象,这本质上就是$\boldsymbol{a},\boldsymbol{b}$构成的二维子平面下的向量变换(比如旋转或者镜面反射)问题,所以我们先考虑$d=2$的情形。
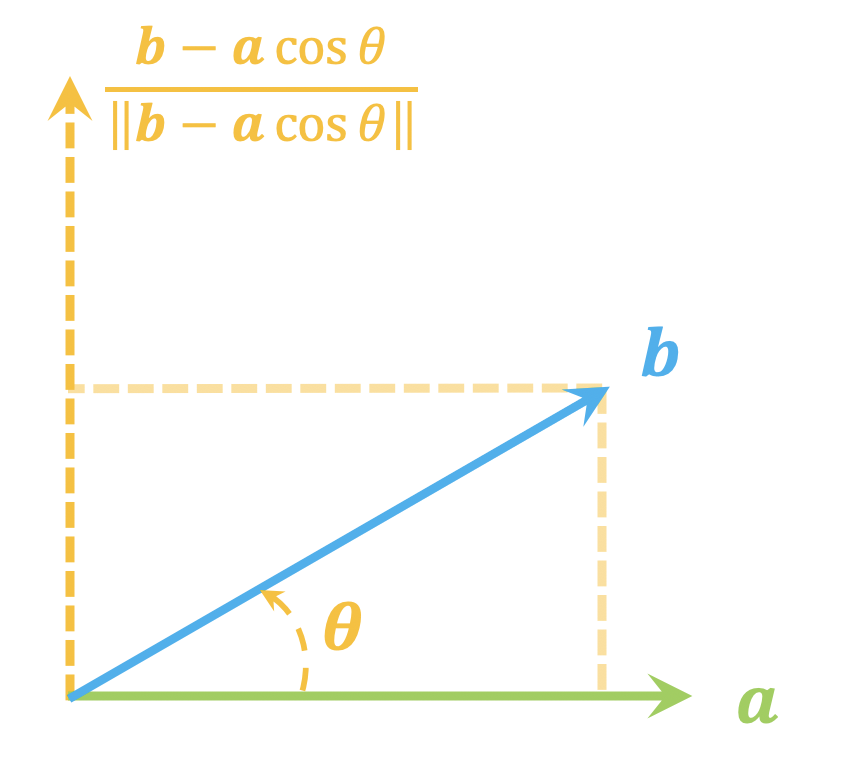
正交分解示意图
10
May
Transformer升级之路:4、二维位置的旋转式位置编码
By 苏剑林 | 2021-05-10 | 60430位读者 | 引用在之前的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中我们提出了旋转式位置编码RoPE以及对应的Transformer模型RoFormer。由于笔者主要研究的领域还是NLP,所以本来这个事情对于笔者来说已经完了。但是最近一段时间,Transformer模型在视觉领域也大火,各种Vision Transformer(ViT)层出不穷,于是就有了问题:二维情形的RoPE应该是怎样的呢?
咋看上去,这个似乎应该只是一维情形的简单推广,但其中涉及到的推导和理解却远比我们想象中复杂,本文就对此做一个分析,从而深化我们对RoPE的理解。
二维RoPE
什么是二维位置?对应的二维RoPE又是怎样的?它的难度在哪里?在这一节中,我们先简单介绍二维位置,然后直接给出二维RoPE的结果和推导思路,在随后的几节中,我们再详细给出推导过程。
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 35201位读者 | 引用标准Attention的$\mathscr{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
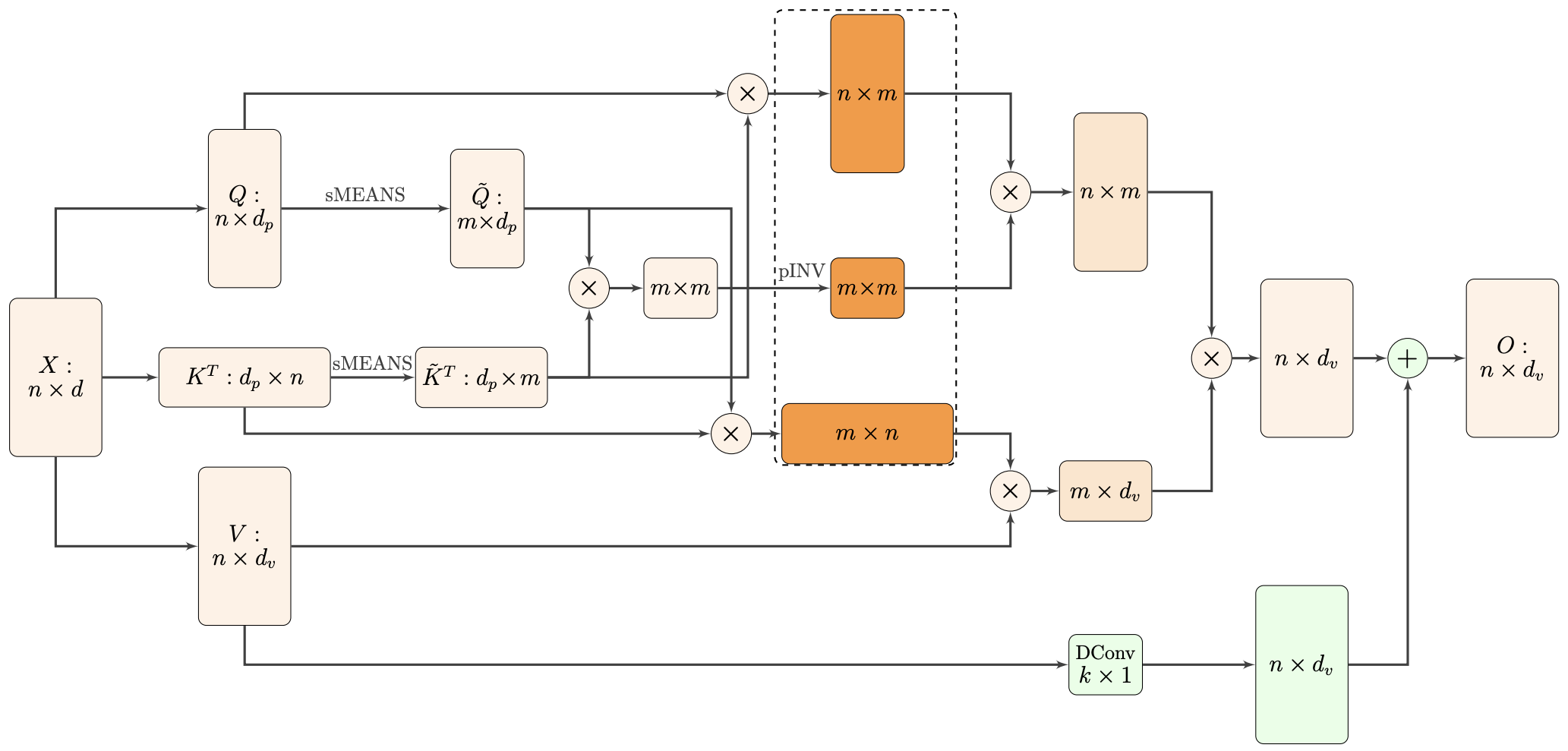
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
26
Jan
Seq2Seq重复解码现象的理论分析尝试
By 苏剑林 | 2021-01-26 | 25676位读者 | 引用去年笔者写过博文《如何应对Seq2Seq中的“根本停不下来”问题?》,里边介绍了一篇论文中对Seq2Seq解码不停止现象的处理,并指出那篇论文只是提了一些应对该问题的策略,并没有提供原理上的理解。近日,笔者在Arixv读到了AAAI 2021的一篇名为《A Theoretical Analysis of the Repetition Problem in Text Generation》的论文,里边从理论上分析了Seq2Seq重复解码现象。从本质上来看,重复解码和解码不停止其实都是同理的,所以这篇新论文算是填补了前面那篇论文的空白。
经过学习,笔者发现该论文确实有不少可圈可点之处,值得一读。笔者对原论文中的分析过程做了一些精简、修正和推广,将结果记录成此文,供大家参考。此外,抛开问题背景不讲,读者也可以将本文当成一节矩阵分析习题课,供大家复习线性代数哈~

最近评论