






14
Jan
【搜出来的文本】⋅(二)从MCMC到模拟退火
By 苏剑林 | 2021-01-14 | 37231位读者 | 引用在上一篇文章中,我们介绍了“受限文本生成”这个概念,指出可以通过量化目标并从中采样的方式来无监督地完成某些带条件的文本生成任务。同时,上一篇文章还介绍了“重要性采样”和“拒绝采样”两个方法,并且指出对于高维空间而言,它们所依赖的易于采样的分布往往难以设计,导致它们难以满足我们的采样需求。
此时,我们就需要引入采样界最重要的算法之一“Markov Chain Monte Carlo(MCMC)”方法了,它将马尔可夫链和蒙特卡洛方法结合起来,使得(至少理论上是这样)我们从很多高维分布中进行采样成为可能,也是后面我们介绍的受限文本生成应用的重要基础算法之一。本文试图对它做一个基本的介绍。
马尔可夫链
马尔可夫链实际上就是一种“无记忆”的随机游走过程,它以转移概率$p(\boldsymbol{y}\leftarrow\boldsymbol{x})$为基础,从一个初始状态$\boldsymbol{x}_0$出发,每一步均通过该转移概率随机选择下一个状态,从而构成随机状态列$\boldsymbol{x}_0, \boldsymbol{x}_1, \boldsymbol{x}_2, \cdots, \boldsymbol{x}_t, \cdots $,我们希望考察对于足够大的步数$t$,$\boldsymbol{x}_t$所服从的分布,也就是该马尔可夫链的“平稳分布”。
7
Jan
【搜出来的文本】⋅(一)从文本生成到搜索采样
By 苏剑林 | 2021-01-07 | 44821位读者 | 引用最近,笔者入了一个新坑:基于离散优化的思想做一些文本生成任务。简单来说,就是把我们要生成文本的目标量化地写下来,构建一个分布,然后搜索这个分布的最大值点或者从这个分布中进行采样,这个过程通常不需要标签数据的训练。由于语言是离散的,因此梯度下降之类的连续函数优化方法不可用,并且由于这个分布通常没有容易采样的形式,直接采样也不可行,因此需要一些特别设计的采样算法,比如拒绝采样(Rejection Sampling)、MCMC(Markov Chain Monte Carlo)、MH采样(Metropolis-Hastings Sampling)、吉布斯采样(Gibbs Sampling),等等。
有些读者可能会觉得有些眼熟,似乎回到了让人头大的学习LDA(Latent Dirichlet Allocation)的那些年?没错,上述采样算法其实也是理解LDA模型的必备基础。本文我们就来回顾这些形形色色的采样算法,它们将会出现在后面要介绍的丰富的文本生成应用中。
1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 163987位读者 | 引用“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 56940位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 103077位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。
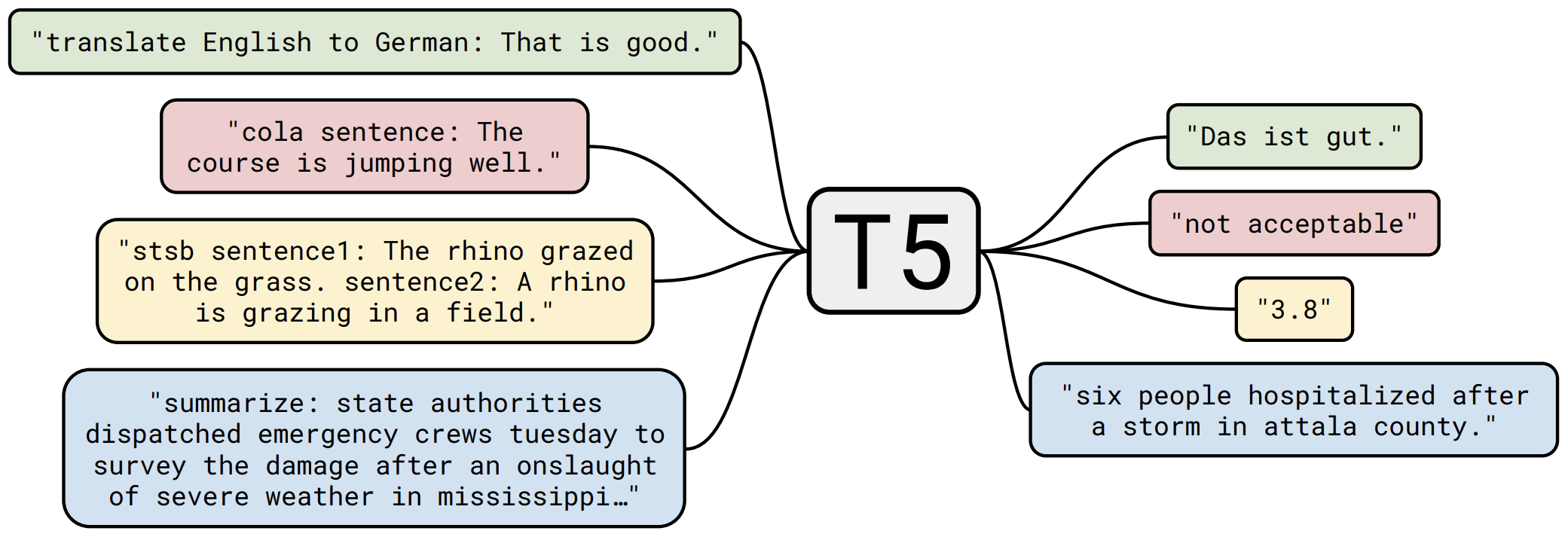
“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
27
Oct
TeaForN:让Teacher Forcing更有“远见”一些
By 苏剑林 | 2020-10-27 | 30044位读者 | 引用Teacher Forcing是Seq2Seq模型的经典训练方式,而Exposure Bias则是Teacher Forcing的经典缺陷,这对于搞文本生成的同学来说应该是耳熟能详的事实了。笔者之前也曾写过博文《Seq2Seq中Exposure Bias现象的浅析与对策》,初步地分析过Exposure Bias问题。
Teacher Forcing示意图
本文则介绍Google新提出的一种名为“TeaForN”的缓解Exposure Bias现象的方案,来自论文《TeaForN: Teacher-Forcing with N-grams》,它通过嵌套迭代的方式,让模型能提前预估到后$N$个token(而不仅仅是当前要预测的token),其处理思路上颇有可圈可点之处,值得我们学习。
(注:为了尽量跟本博客旧文章保持一致,本文的记号与原论文的记号有所不同,请大家以理解符号含义为主,不要强记符号形式。)
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 52860位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。
7
Sep

最近评论